





 Оставить комментарий
Оставить комментарий
В статье рассказывается:
- Зачем нужна индексация сайта
- Что собой представляет индексация сайта с помощью robots.txt
- Директивы для индексации сайта файлом robots.txt
- Как создать файл robots.txt для начала индексации сайта
- Правильная настройка robots.txt для индексации сайтов на разных движках
- 7 распространенных ошибок при индексации сайта с помощью robots.txt
- Как избежать ошибок, создавая правильную структуру robots.txt для индексации сайта
-
 Чек-лист: Как добиваться своих целей в переговорах с клиентамиСкачать бесплатно
Чек-лист: Как добиваться своих целей в переговорах с клиентамиСкачать бесплатно
Веб-ресурс готов к работе: наполнен качественными уникальными текстами, оригинальными изображениями, по разделам удобно перемещаться, а дизайн радует глаз. Осталось только представить свое детище пользователям Сети. Но первыми с порталом должны познакомиться поисковики.
Процесс знакомства называется индексацией, а одну из главных ролей в нем играет текстовый файл robots. Чтобы индексация сайта robots.txt прошла успешно, необходимо соблюсти ряд специфических требований.
Зачем нужна индексация сайта
Движок веб-ресурса (CMS) является одним из факторов, существенно влияющих на скорость индексации поисковыми пауками. Почему важно указывать краулерам путь только на важные страницы, которые должны появляться в выдаче?
Робот поисковика просматривает лимитированное число файлов на конкретном ресурсе, после чего переходит на следующий сайт. При отсутствии заданных ограничений поисковый паучок может начать с индексации файлов движка, количество которых порой исчисляется тысячами, — на основной контент у робота просто не останется времени.
Либо он проиндексирует совсем не те страницы, по которым вы планируете продвигаться. Еще хуже, если поисковики увидят столь нелюбимое ими дублирование контента, когда разные ссылки ведут на один и тот же (или почти идентичный) текст или картинку.
Поэтому запретить паукам поисковика видеть лишнее — необходимость. Для этого и предназначен robots.txt — обычный текстовый файл, название которого пишется строчными буквами без использования заглавных. Он создается в любом текстовом редакторе (Notepad++, SciTE, VEdit и др.), здесь же редактируется. Файл позволяет оказывать влияние на индексацию сайта «Яндексом» и Google.
Программисту, пока не имеющему достаточного опыта, лучше для начала ознакомиться с примерами правильного заполнения файла. Нужно выбрать веб-ресурсы, представляющие для него интерес, и в адресной строке браузера набрать site.ru/robots.txt (где первая часть до «/» — название портала).
Важно отсматривать только сайты, работающие на интересующем вас движке, поскольку папки CMS, запрещенные к индексации, в разных системах управления называются по-разному. Следовательно, отправной точкой становится движок. Если ваш сайт натянут на WordPress, искать нужно блоги, работающие на этом же движке; для Joomla! будет свой идеальный robots и т. д. При этом за образцы желательно принимать файлы порталов, привлекающих существенный трафик из поиска.
Что собой представляет индексация сайта с помощью robots.txt
Поисковая индексация — важнейший показатель, от которого во многом зависит успешность продвижения. Кажется, что сайт создан идеальным: учтены запросы пользователей, содержание контента на высоте, навигация удобна, но сайт никак не может подружиться с поисковиками. Причины нужно искать в технической стороне, конкретно — в инструментах, с помощью которых можно влиять на индексацию.
Их два — Sitemap.xml и robots.txt. Важные, дополняющие друг друга и при этом решающие полярные задачи файлы. Карта сайта приглашает поисковых пауков: «Добро пожаловать, проиндексируйте, пожалуйста, все эти разделы», выдавая ботам URL-адреса каждой страницы, подлежащей индексации, и время ее последнего обновления. Файл robots.txt, напротив, служит знаком «Стоп», запрещая паукам самовольное шествие по любым частям сайта.

Источник: shutterstock.com
Данный файл и похожий по названию метатег robots, позволяющий проводить более тонкие настройки, содержат четкие инструкции для краулеров поисковых систем, указывая запреты на индексацию определенных страниц или целых разделов.
Правильно установленные ограничения наилучшим образом отразятся на индексировании сайта. Хотя еще встречаются дилетанты, полагающие, что можно позволить ботам изучать абсолютно все файлы. Но в данной ситуации количество внесенных в базу поисковика страниц не означает высокого качества индексирования. Зачем, к примеру, роботам административная и технические части сайта или страницы печати (пользователю они удобны, а поисковикам представляются как дублированный контент)? Есть масса страниц и файлов, на которые боты тратят время, по сути, впустую.
Посещая ваш сайт, поисковый паук сразу ищет предназначенный для него файл robots.txt. Не найдя документ или найдя его в некорректном виде, бот начинает действовать самостоятельно, индексируя буквально все подряд по ведомому лишь ему алгоритму. Совсем не обязательно он начнет с нового контента, о котором вы желали бы уведомить пользователей в первую очередь. Индексация в лучшем случае просто затянется, в худшем — может обернуться еще и штрафными санкциями за дубли.
Наличие правильного текстового файла robots позволит избежать многих проблем.
Как скрыть сайт от индексации robots.txt
Запретить индексацию разделов или страниц веб-ресурса можно тремя способами, от точечного до высокоуровневого:
Тег noindex и атрибут rel="nofollow" — это абсолютно разные элементы кода, преследующие разные цели, но являющиеся одинаково ценными помощниками СЕО-оптимизаторов. Вопрос их обработки поисковиками стал уже едва ли не философским, но факт остается фактом: noindex позволяет спрятать от роботов часть текста (в стандартах html его нет, но для «Яндекса» точно работает), а nofollow запрещает переходить по ссылке и передавать ее вес (входит в стандартную классификацию, валиден для всех поисковиков).
Метатег robots, прописанный на конкретной странице, оказывает влияние именно на нее. Ниже подробнее рассмотрим, как в нем обозначить запрет индексации и перехода по ссылкам, находящимся в документе. Метатег полностью валидный, системы учитывают (или стараются брать в расчет) указанные данные. Причем Google, выбирая между robots в виде файла в корневом каталоге сайта и метатега страницы, приоритет отдает последнему.
robots.txt — данный метод полностью валиден, поддерживается всеми поисковыми системами и другими обитающими в Сети ботами. Тем не менее его директивы не всегда расцениваются как приказ к исполнению (про неавторитетность для Google сказано выше). Правила индексации, прописанные в файле, действительны для сайта в целом: отдельных страниц, каталогов, разделов.
из разных ниш с ростом
от 89% до 1732%
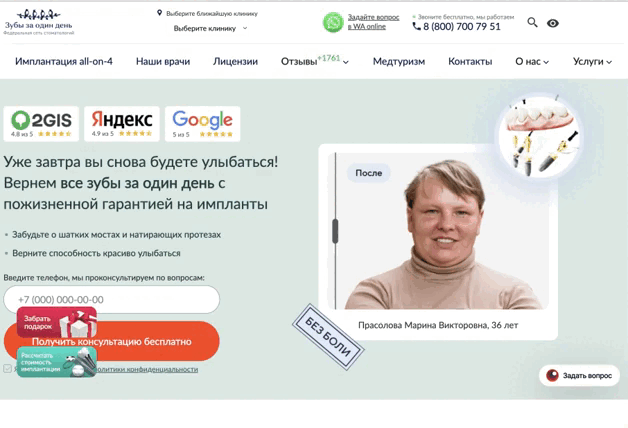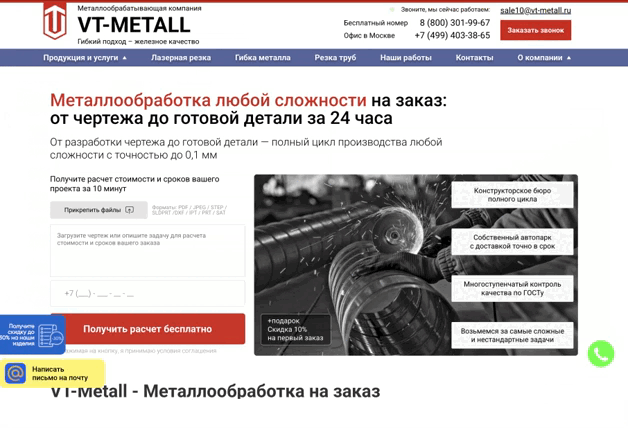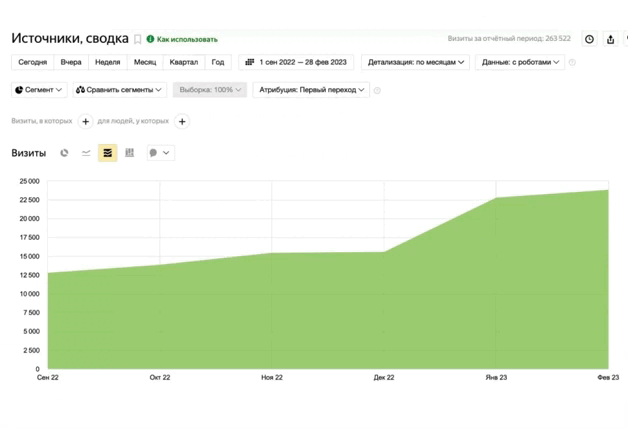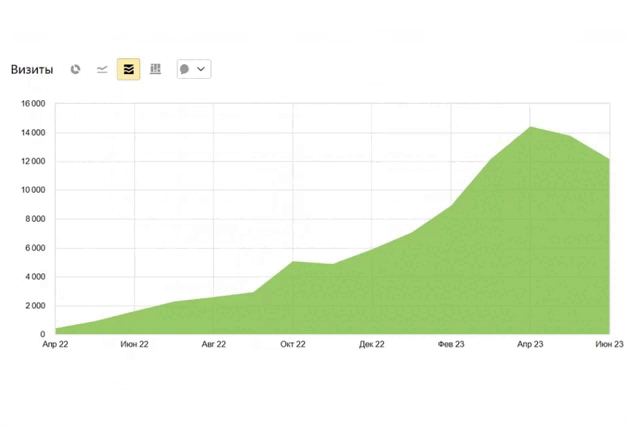

На примерах рассмотрим запрет на индексацию портала и его частей.
Полный запрет индексации сайта robots.txt
Есть масса причин, чтобы запретить паукам индексировать веб-сайт. Он еще в разработке, проводится редизайн или модернизация, ресурс является экспериментальной площадкой, не предназначенной для пользователей.
Закрыть сайт от индексации robots.txt может для всех поисковиков, для отдельного робота или запретить для всех, кроме одного.
| Не разрешать индексацию никому |
User-agent: * Disallow: / |
|
Не разрешать индексацию отдельному боту |
User-agent: YandexImages |
|
Разрешить индексацию только одному боту |
User-agent: * |
Как запретить индексацию сайта robots.txt на отдельных страницах
Если ресурс небольшой, то прятать страницы вряд ли потребуется (что там скрывать на сайте-визитке), а крупным порталам, содержащим солидный объем служебной информации, без запретов не обойтись. Необходимо закрыть от роботов:
административную панель;
служебные каталоги;
поиск на сайте;
личный кабинет;
формы регистрации;
формы заказа;
сравнение товаров;
избранное;
корзину;
капчу;
всплывающие окна и баннеры;
идентификаторы сессий.
Неактуальные новости и события, мероприятия в календаре, акции, спецпредложения — это так называемые мусорные страницы, которые лучше всего прятать. Устаревший контент на информационных сайтах тоже лучше закрывать, чтобы не допустить негативных оценок со стороны поисковиков. Старайтесь, чтобы обновления были регулярными, — тогда и играть в прятки с поисковыми системами не придется.
Запрет роботам на индексацию:
| Конкретной страницы |
User-agent: * Disallow: /contact.html |
|
Конкретного раздела |
User-agent: * |
|
Всего веб-ресурса, кроме одного раздела |
User-agent: * |
|
Всего раздела, кроме одного подраздела |
User-agent: * |
|
Поиска на сайте |
User-agent: * |
|
Панели администратора |
User-agent: * |
Как закрыть другую информацию
В robots.txt можно прописать полные или выборочные запреты индексирования папок, файлов, скриптов, utm-меток, которые могут быть приказом как для отдельных поисковых пауков, так и для роботов всех систем.

Источник: shutterstock.com
Запрещение индексировать:
| Тип файлов |
User-agent: * Disallow: /*.jpg |
|
Папку |
User-agent: * |
|
Папку, кроме одного файла |
User-agent: * |
|
Скрипты |
User-agent: * |
|
utm-метки |
User-agent: * |
|
utm-метки для «Яндекса» |
Clean-Param: utm_source&utm_medium&utm_campaign |
Как закрыть сайт от индексации, используя метатеги
Метатег robots служит альтернативой одноименному текстовому файлу. Прописывается в исходном коде веб-ресурса (в файле index.html), размещается в контейнере <head>. Необходимо уточнить, кому нельзя индексировать сайт. Если запрет общий, вписывается robots; если вход воспрещен только одному краулеру, нужно указать его имя (Google — Googlebot, «Яндекс» — Yandex).
Возможны два варианта записи метатега.
Первый:
<metaname=”robots” content=”noindex, nofollow”/>
Второй:
<meta name=”robots” content=”none”/>
Для атрибута “content” могут применяться значения:
none — запрет индексации (включая noindex и nofollow);
noindex — запрет индексации содержимого;
nofollow — запрет индексации ссылок;
follow — разрешение индексировать ссылки;
index— разрешить индексацию содержимого;
all— разрешить индексацию содержимого и ссылок.
Для разных случаев нужно использовать сочетания значений. Например, при запрете на индексацию содержимого требуется разрешить ботам индексировать ссылки: content=”noindex, follow”.

Источник: shutterstock.com
Закрывая веб-сайт от поисковиков через метатеги, владельцу не нужно создавать robots.txt в корне.
Нужно помнить, что в вопросе индексации многое зависит от «вежливости» паука. Если он «воспитанный», то прописанные мастером правила будут актуальны. Но в целом валидность директив robots (и файла, и метатега) не означает стопроцентного следования им. Даже для поисковых систем не каждый запрет является железным, а уж про различного рода воришек контента говорить не приходится. Они изначально настроены на то, чтобы обойти все запреты.
К тому же далеко не все краулеры интересуются контентом. Для одних важны только ссылки, для других — микроразметка, третьи проверяют зеркальные копии сайтов и проч. При этом пауки систем вовсе не ползают по сайту, как вирусы, а в удаленном режиме запрашивают нужные страницы. Поэтому чаще всего никаких проблем владельцам ресурсов они не создают. Но, если при проектировании робота допущены ошибки или возникла какая-то внешняя нестандартная ситуация, краулер может существенно нагрузить индексируемый портал.
Директивы для индексации сайта файлом robots.txt
Используемые команды:
«User-agent:»
Основное руководящее указание файла robots.txt. Используется для конкретизации. Вписывается название бота, для которого далее последуют указания. Например:
User-agent: Googlebot— базовая директива в таком виде обозначает, что все следующие команды касаются только индексирующего робота Google;
User-agent: Yandex— прописанные разрешения и запреты предназначены для робота «Яндекса».
Запись User-agent: * означает обращение ко всем остальным поисковым системам (специальный символ «*» обозначает «любой текст»). Если принять во внимание приведенный выше пример, то звездочка обозначит все поисковики, кроме «Яндекса». Потому что Google вполне обходится без личного обращения, довольствуясь общим обозначением «любой текст».
«Disallow:»
Самая распространенная команда, запрещающая индексацию. Обратившись к роботу в «User-agent:», далее программист указывает, что не разрешает боту индексировать часть сайта или весь сайт (при этом указывается путь от корня). Поисковый паук понимает это по расширению команды. Разберемся и мы.
User-agent: Yandex
Disallow: /
Если в robots.txt есть такая запись, то поисковый бот «Яндекса» понимает, что ему нельзя проводить индексацию веб-ресурса как такового: после запрещающего знака «/» не стоит никаких уточнений.
User-agent: Yandex
Disallow: /wp-admin
В данном примере уточнения есть: запрет на индексацию касается только системной папки wp-admin (сайт работает на движке WordPress). Робот «Яндекса» видит команду и не индексирует указанную папку.
User-agent: Yandex
Disallow: /wp-content/themes
Эта директива указывает краулеру, что он может индексировать все содержимое «wp-content», за исключением «themes», что робот и сделает.
User-agent: Yandex
Disallow: /index$
Появляется еще один важный символ «$», который позволяет проявить гибкость в запретах. В данном случае робот понимает, что ему нельзя индексировать страницы, в ссылках которых имеется последовательность букв «index». Отдельный файл с аналогичным названием «index.php» индексировать можно, и робот это четко понимает.
Можно ввести запрет индексации отдельных страниц ресурса, в ссылках которых содержатся определенные символы. Например:
User-agent: Yandex
Disallow: *&*
Робот «Яндекса» так прочитывает команду: не индексировать все страницы с URL-адресами, содержащими «&», стоящий между любыми другими символами.
User-agent: Yandex
Disallow: *&
В данном случае робот понимает, что нельзя индексировать страницы только в том случае, если их адреса заканчиваются на «&».

Источник: shutterstock.com
Почему нельзя индексировать системные файлы, архивы, личные данные пользователей, думаем, понятно — это не тема для дискуссий. Поисковому боту совершенно ни к чему тратить время на проверку никому не нужных данных. А вот относительно запретов на индексацию страниц многие задают вопросы: чем обусловлена целесообразность запретительных директив? Опытные разработчики могут привести десяток различных доводов в пользу табуирования индексации, но главным будет необходимость избавиться от дублей страниц в поиске. Если таковые имеются, это резко отрицательно сказывается на ранжировании, релевантности и прочих важных аспектах. Поэтому внутренняя SEO-оптимизация немыслима без robots.txt, в котором бороться с дубликатами довольно просто: нужно лишь грамотно использовать директиву «Disallow:» и специальные символы.
«Allow:»
Волшебный файлик robots позволяет не только спрятать от поисковиков ненужное, но и открыть сайт для индексации. robots.txt, содержащий команду «Allow:», указывает паукам поисковиков, какие элементы веб-ресурса нужно обязательно внести в базу. На помощь приходят те же уточнения, что и в предыдущей команде, только теперь они расширяют спектр разрешений для краулеров.
Возьмем один из примеров, приведенных в предыдущем пункте, и увидим, как меняется ситуация:
User-agent: Yandex
Allow: /wp-admin
Если «Disallow:» означало запрет, то теперь содержимое системной папки wp-admin становится достоянием «Яндекса» на законных основаниях и может появиться в поисковой выдаче.
Но на практике данная команда применяется редко. Этому есть вполне логичное объяснение: отсутствие запрета, обозначенного «Disallow:», позволяет поисковым паукам рассматривать весь сайт как разрешенный к индексации. Отдельная директива для этого не требуется. При наличии запретов не попавший под них контент роботы также по умолчанию индексируют.
Директивы «Host:» и «Sitemap:»
Еще две важнейшие команды для поисковых пауков. «Host:» — целевая директива для отечественного поисковика. «Яндекс» руководствуется ею при определении главного зеркала веб-ресурса, чей адрес (с www или без) будет участвовать в поиске.
Рассмотрим на примере PR-CY.ru:
User-agent: Yandex
Host: pr-cy.ru
или:
User-agent: Yandex
Host:
Директива используется, чтобы избежать дублирования содержимого ресурса.
Команда «Sitemap:» помогает роботам правильно двигаться к карте сайта — специальному файлу, представляющему собой иерархическую структуру страниц, тип контента, сведения о частоте обновления и др. Навигатором для поисковых пауков служит файл sitemap.xml (на вордпрессовском движке sitemap.xml.gz), к которому им нужно добраться как можно быстрее. Тогда ускорится индексация не только карты сайта, но и всех остальных страниц, которые не замедлят появиться в выдаче.
Гипотетический пример:
User-agent: *
Sitemap:
Sitemap:
Команды, которые обозначаются в текстовом файле robots и воспринимаются «Яндексом»:
| Директива | Что делает |
|
User-agent * |
Называет поискового паука, для которого написаны правила, перечисленные в файле. |
|
Disallow |
Обозначает запрет для роботов на индексацию сайта, его разделов или отдельных страниц. |
|
Sitemap |
Указывает путь к карте сайта, размещенной на веб-ресурсе. |
|
Clean-param |
Содержит следующую информацию для поискового паука: URL-адрес страницы включает параметры, не подлежащие индексации (например, UTM-метки). |
|
Allow |
Дает разрешение на индексацию разделов и страниц веб-ресурса. |
|
Crawl-delay |
Позволяет отсрочить сканирование. Обозначает временной минимум (в секундах) для поискового робота между загрузками страниц: проверив одну, паук ожидает заданное количество времени перед запросом следующей страницы из списка. |
*Обязательная директива.
Чаще остальных обычно бывают востребованы команды Disallow, Sitemap и Clean-param. Рассмотрим на примере:
User-agent: * #указание роботов, которым предназначены последующие команды.
Disallow: /bin/ # запрет индексаторам сканировать ссылки из «Корзины покупок».
Disallow: /search/ # запрет на индексацию страниц поиска по сайту.
Disallow: /admin/ # запрет на выдачу в поиске административной панели.
Sitemap: # обозначает путь к карте сайта для краулера.
Clean-param: ref /some_dir/get_book.pl
Напомним, приведенные интерпретации директив актуальны для «Яндекса» — пауки других поисковиков могут читать команды иначе.
Как создать файл robots.txt для начала индексации сайта
Теоретическая база создана — настало время составить идеальный (ну, или очень близкий к этому) текстовый файл robots. Если сайт работает на движке (Joomla!, WordPress и др.), он снабжается массой объектов, без которых невозможна нормальная работа. Но информативной составляющей в таких файлах нет.
В большинстве CMS хранилищем контента является база данных, но добраться до нее роботы не могут. И продолжают искать контент в движковых файлах. Соответственно, время, выделенное на индексацию, расходуется впустую.
Очень важно стремиться к уникальности контента своего веб-ресурса, тщательно отслеживая появление дублей. Даже частичное повторение информационного содержимого сайта не лучшим образом сказывается на его оценке поисковиками. Если один и тот же контент можно найти по разным URL-адресам, это тоже расценивается как дублирование.
Два главных поисковика, «Яндекс» и Google, неизбежно выявят дублирование во время сканирования и искусственно понизят позиции веб-ресурса в выдаче.

Источник: shutterstock.com
Не забывайте про замечательный инструмент, помогающий справляться с дублированием, — метатег Canonical. Прописав в нем другой URL, веб-мастер таким образом указывает поисковому пауку предпочтительную для индексирования страницу, которая и будет канонической.
К примеру, страница с пагинацией содержит метатег Canonical, указывающий на , что позволяет исключить проблемы с дублированием заголовков.
<link rel="canonical" href="; />
Итак, собираем воедино все полученные теоретические знания и приступаем к практическому их воплощению в robots.txt для вашего веб-ресурса, специфика которого обязательно должна быть учтена. Что потребуется для данного важного файла:
текстовый редактор (Notepad или любой другой) для написания и редактирования robots;
тестировщик, который поможет найти ошибки в созданном документе и проверит корректность запретов на индексацию (например, Яндекс.Вебмастер);
FTP-клиент, упрощающий закачку готового и проверенного файла в корень веб-ресурса (если сайт работает на WordPress, то чаще всего robots хранится в системной папке Public_html).
Первое, что делает поисковый краулер — запрашивает файл, созданный специально для него и находящийся по URL «/robots.txt».
| URL сайта | URL файла robots.txt на сайте |
|
|
|
|
|
|
|
|
|
|
|
|
Веб-ресурс может содержать единственный файл «/robots.txt». Не нужно помещать его в пользовательские поддиректории, где пауки все равно не будут искать документ. Если есть желание создавать robots именно в поддиректориях, нужно помнить, что все равно потребуется собирать их в единый файл в корневой папке. Использование метатега «Robots» целесообразнее.
URL чутко относятся к буквенному регистру — помните, что «/robots.txt» пишется без использования заглавных букв.
Теперь нужно набраться терпения и дождаться поисковых пауков, которые первым делом изучат ваш созданный по всем правилам, корректный robots.txt и приступят к сканированию вашего веб-портала.
Правильная настройка robots.txt для индексации сайтов на разных движках
Если у вас коммерческий ресурс, то создание файла robots следует доверить опытному SEO-специалисту. Это особенно важно, если проект сложный. Тем, кто не готов принять сказанное за аксиому, поясним: данный важный текстовый файл оказывает серьезное влияние на индексацию ресурса поисковиками, от его правильности зависит скорость обработки сайта ботами, а содержимое robots обладает своей спецификой. Разработчику необходимо учесть тип сайта (блог, интернет-магазин и проч.), движок, структурные особенности и другие важные аспекты, что начинающему мастеру может оказаться не по силам.
При этом нужно принять важнейшие решения: что закрыть от сканирования, что оставить видимым для краулеров, чтобы страницы появились в поиске. Неопытному сеошнику будет весьма проблематично справиться с таким объемом работы.
Правильный пример robots.txt для WordPress
User-agent:* # общие правила для роботов, кроме «Яндекса» и Google,
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архивавтора
Disallow: /users/ # архивавторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rssфид
Disallow: */embed # всевстраивания
Disallow: */wlwmanifest.xml # xml-файлманифеста Windows Live Writer (если не используете, # правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылкисutm-метками
Disallow: *openstat= # ссылкисметкамиopenstat
Allow: */uploads # открываем папку с файлами uploads
Sitemap: # адрес карты сайтаUser-agent: GoogleBot& # правила для Google
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploadsAllow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т. д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т. д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т. д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т. д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSSUser-agent: Yandex # правила для «Яндекса»
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндексрекомендуетнезакрывать# от индексирования, а удалять параметры меток, # Google такие правила не поддерживает
Clean-Param: openstat # аналогично
Robots.txt, пример для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Sitemap: XML-формата
Источник: shutterstock.com
Robots.txt, пример для Bitrix
User-agent: *
Disallow: /*index.php$
Disallow: /bitrix/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*?action=
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*COURSE_ID=
Disallow: /*?COURSE_ID=
Disallow: /*?PAGEN
Disallow: /*PAGEN_1=
Disallow: /*PAGEN_2=
Disallow: /*PAGEN_3=
Disallow: /*PAGEN_4=
Disallow: /*PAGEN_5=
Disallow: /*PAGEN_6=
Disallow: /*PAGEN_7=
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*SHOWALL
Disallow: /*show_all=
Sitemap: XML-форматаRobots.txt, пример для MODx
User-agent: *
Disallow: /assets/cache/
Disallow: /assets/docs/
Disallow: /assets/export/
Disallow: /assets/import/
Disallow: /assets/modules/
Disallow: /assets/plugins/
Disallow: /assets/snippets/
Disallow: /install/
Disallow: /manager/
Sitemap:Robots.txt, пример для Drupal
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Allow: /*?page=
Disallow: /*?
Sitemap: к вашей карте XML формата
ВНИМАНИЕ! Системы управления содержимым сайта постоянно обновляются, поэтому и файл robots может видоизменяться: могут закрываться дополнительные страницы или группы файлов либо, наоборот, открываться для индексации. Это зависит от целей веб-ресурса и актуальных изменений движка.
7 распространенных ошибок при индексации сайта с помощью robots.txt
Допускаемые при создании файла ошибки становятся причиной некорректного функционирования robots.txt или вообще приводят к невозможности работы файла.
Какие ошибки возможны:
Логические (обозначенные правила вступают в противоречие). Выявить данный тип ошибок можно в ходе проверки в Яндекс.Вебмастере и GoogleRobotsTestingTool.
Синтаксические (директивы записаны с ошибками).
Чаще остальных встречаются:
в записи не учтен регистр букв;
использованы заглавные буквы;
все правила перечислены в одной строке;
правила не разделены пустой строкой;
указание краулера в директиве;
каждый файл папки, требующей закрытия, перечисляется отдельно;
обязательная директива Disallow не прописана.
Рассмотрим частые ошибки, их последствия и, самое главное, меры по их недопущению на своем веб-ресурсе.
Расположение файла.URL файла должен быть такого вида: (вместо site.ru значится адрес вашего сайта). Файл robots.txt базируется исключительно в корневой папке ресурса — в противном случае поисковые пауки его не увидят. Не получив запретов, они станут сканировать весь сайт и даже те файлы и папки, которые вы хотели бы спрятать от выдачи в поиске.
Чувствительность к регистру.Никаких заглавных букв. — неправильно. В таком случае робот поисковой системы получит в качестве ответа сервера 404 (страница ошибки) или 301 (переадресация). Сканирование будет проходить без учета директив, обозначенных в robots. Если все сделано правильно, ответ сервера носит код 200, при котором владелец ресурса сможет управлять поисковым краулером. Единственный верный вариант — «robots.txt».
Открытие на странице браузера.Поисковые пауки смогут верно прочитать и использовать директивы файла robots.txt, только если он открывается на странице браузера. Важно уделить пристальное внимание серверной части движка. Иногда к скачиванию предлагается именно файл данного типа. Тогда следует настроить показ — в противном случае роботы будут сканировать сайт как им вздумается.
Ошибки запрета и разрешения.«Disallow» — директива для запрета сканирования сайта или его разделов. К примеру, нужно запретить роботам индексацию страниц с результатами поиска по сайту. В таком случае файл robots.txt должен содержать строчку: «Disallow: /search/». Краулер понимает, что все страницы, где встречается «поиск», запрещены к сканированию. При тотальном запрете индексирования прописывается Disallow: /. А вот разрешающую директиву «Allow» ставить в данном случае не нужно. Хотя нередки случаи, когда команду записывают так: «Allow:», предполагая, что робот воспримет это как разрешение на индексацию «ничего». Разрешить к индексации весь сайт можно через директиву «Allow: /». Не нужно путать команды. Это приводит к ошибкам в сканировании пауками, в итоге добавляющими в выдачу абсолютно не те страницы, по которым должно идти продвижение.
Совпадение директив.Disallow: и Allow: для одной страницы встречаются в robots, что заставляет краулеры отдавать приоритет разрешающей директиве. К примеру, изначально раздел был открыт для сканирования пауками. Потом по каким-то причинам было принято решение спрятать его от индекса. Естественно, в файл robots.txt добавляется запрет, но разрешение веб-мастер убрать забывает. Для поисковиков запрет не так важен: они предпочитают проиндексировать страницу в обход исключающих друг друга команд.
Директива Host:.Распознается только пауками «Яндекса» и используется для определения главного зеркала. Полезная команда, но, увы, всем другим поисковикам она представляется ошибочной или неизвестной. Привлекая ее в свой robots, оптимально указать в качестве User-agent: все и робот Yandex, для которого персонально прописать команду Host:
User-Agent: Yandex
Host: site.ruДиректива, прописанная для всех краулеров, будет воспринята ими как ошибочная.
Директива Sitemap:.С помощью карты сайта боты узнают, какие страницы есть на веб-ресурсе. Весьма распространенной ошибкой является невнимание разработчиков к месторасположению файла sitemap.xml, хотя именно оно определяет перечень включаемых в карту URL. Размещая файл вне корневой папки, разработчики сами подвергают сайт риску: краулеры неправильно определяют число страниц, в результате важные части веб-ресурса не попадают в выдачу.
К примеру, располагая файл Sitemap в каталоге по URL-адресу , можно включить в него любые URL-адреса, начинающиеся с ... А URL вида, допустим, ... не должны быть включены в перечень.

Подведем итог. Если владелец сайта желает воздействовать на процесс индексации веб-ресурса поисковыми ботами, файл robots.txt приобретает особенную важность. Необходимо тщательно проверить созданный документ на предмет логических и синтаксических ошибок, чтобы в итоге директивы работали на общий успех вашего сайта, обеспечивая качественное и быстрое индексирование.
Как избежать ошибок, создавая правильную структуру robots.txt для индексации сайта
Структура robots.txt понятна и проста, написать файл самостоятельно вполне возможно. Нужно только тщательно следить за предельно важным для robots синтаксисом. Поисковые боты следуют директивам документа добровольно, но синтаксис поисковики трактуют по-разному.
Перечень следующих правил, обязательных к исполнению, поможет исключить наиболее частые ошибки при создании robots.txt. Чтобы написать правильный документ, следует помнить, что:
каждая директива начинается с новой строки;
в одной строке — не более одной команды;
в начале строки нельзя ставить пробел;
параметр команды должен быть в одну строку;
параметры директив не нужно брать в кавычки;
параметры команд не требуют точки с запятой в завершение;
директива в robots.txt указывается в формате: [Имя_команды]:[необязательный пробел][значение][необязательный пробел];
после знака решетки # допускаются комментарии в robots.txt;
пустая строка может быть расценена как окончание команды User-agent;
запрещающая директива с пустым значением — «Disallow: » аналогична разрешающей сканировать весь сайт директиве «Allow: /»;
директивы «Allow», «Disallow» могут содержать не более одного параметра. Каждый новый параметр записывается с новой строки;
в названии файла robots.txt используются только строчные буквы. Robots.txt или ROBOTS.TXT — ошибочные написания;
стандарт robots.txt не регламентирует чувствительность к регистру, а вот файлы и папки часто бывают щепетильны в этом вопросе. Поэтому, хотя в названии команд и параметров допустимо использование заглавных букв, это считается дурным тоном. Лучше не увлекаться верхним регистром;
когда параметр команды является папкой, перед названием обязателен слеш «/», например: Disallow: /category;
если файл robots.txt весит больше 32 Кб, поисковые боты воспринимают его равнозначным «Disallow: » и считают полностью разрешающим индексацию;
недоступность robots.txt (по разным причинам) может восприниматься краулерами как отсутствие запретов на сканирование;
пустой robots.txt расценивается как разрешающий индексацию сайта в целом;
если несколько команд «User-agent» перечислены без пустой строки между ними, поисковые пауки могут воспринять первую директиву в качестве единственной, проигнорировав все последующие «User-agent»;
в robots.txt не допускается использование любых символов национальных алфавитов.
Приведенные правила актуальны не для всех поисковиков, потому что они по-разному интерпретируют синтаксис robots.txt. К примеру, «Яндекс» выделяет записи по наличию в строке «User-agent», поэтому для него не имеет значения наличие пустой строки между разными директивами «User-agent».
В целом robots должен содержать только то, что действительно нужно для правильной индексации. Не нужно пытаться объять необъятное и вместить в документ максимум данных. Лучший robots.txt — наполненный смыслом файл, количество строк роли не играет.
Текстовый документ robots необходимо проверить на правильность структуры и корректность синтаксиса, в чем помогут представленные в Сети сервисы. Для этого нужно загрузить robots.txt в корневую папку своего сайта, иначе сервис может сообщить, что ему не удалось загрузить требуемый документ. Предварительно robots.txt рекомендуется проверить на доступность по адресу нахождения файла (ваш_сайт.ru/robots.txt).
Свои службы анализа сайтов веб-мастерам предлагают крупнейшие поисковые системы «Яндекс» и Google. Одним из аспектов аналитической работы является проверка robots:
В Яндекс.Вебмастере проверить файл можно по адресу .
В Google инструменты для проверки находятся по адресу .
Онлайн-валидаторов robots.txt в Интернете немало, можно выбрать любой понравившийся.














