





 Оставить комментарий
Оставить комментарий
В статье рассказывается:
- Что такое индексация сайта
- Зачем и как закрывать сайт от индексации
- Как закрыть от индексации определенные элементы на страницах сайта
- Основные ошибки при закрытии от индексации отдельных элементов сайта
Увеличение трафика и продвижение страниц сайта в поисковиках – вот, пожалуй, главные цели, стоящие перед каждым владельцем ресурса. Но бывают случаи, когда появление сайта в выдаче нежелательно: например, проходит процесс редизайна или площадка совсем новая, требующая наполнения контентом.
Тогда перед владельцем встает вопрос: что нужно сделать, чтобы поисковые роботы не «обнаружили» ресурс раньше времени? В сегодняшней статье расскажем, как закрыть сайт от индексации, и подробно рассмотрим существующие для этого инструменты.
Что такое индексация сайта
Индексация – процесс, результат которого можно сравнить, например, с рентгеновским снимком. Пауки поисковых систем выступают в роли рентген-аппарата, сканируя страницы ресурса и добавляя информацию о них в общую базу данных (или индекс). Краулеры также исполняют роль доктора, в реальной жизни призванного описать снимок.
Они не просто фиксируют наличие сайта, но и оценивают контент, юзабилити и другие характеристики, которые напрямую влияют на позиции в рейтинге (или поисковой выдаче). Оценив наполнение и классифицировав ресурс как нечто интересное и полезное, роботы предоставят сайту более выгодные места в выдаче и наоборот.

Источник: shutterstock.com
Получая релевантные ответы на запрос, пользователи даже не задумываются, какой объем работы был проведен роботами поисковых систем для составления перечня ресурсов, на которых представлена требуемая информация. Не догадываются посетители и о трудах, затраченных владельцами сайтов, чтобы интернет-площадки занимали лучшие места в выдаче.
Иногда для этого приходится на некоторое время «прятать» ресурс от поисковых ботов для дальнейшей индексации его как полезного и отвечающего всем требованиям посетителей.
У каждой системы разработаны сложнейшие алгоритмы, по которым ведется работа поисковых пауков. Но и «Яндекс», и Google оценивают контент с точки зрения интереса и пользы, приносимой пользователям.
Индексации подвергаются:
-
текст;
-
графика (фотографии и картинки);
-
видео (факт наличия видеоконтента, количество просмотров);
-
мета-теги (указатели для роботов, позволяющие фиксировать их внимание на важных моментах страницы).
Когда информация о сайте заносится в поисковые базы, ресурс включается в рейтинг, который предстает вниманию пользователя в ответ на соответствующий запрос.
Кажется, совсем недавно достаточно было максимально наполнить текст ключевыми словами, чтобы упростить работу поискового паука и спокойно ожидать появления сайта в ТОПе. Теперь перенасыщение ключами не просто не помогает, а является прямой угрозой попадания под санкции.
Поисковые системы уважают пользователей и заботятся об их удобстве. Разве интересно человеку читать текст, состоящий из ключевых фраз, которые никак не согласуются между собой? Конечно, нет. Более того, не понравится подобный текст и роботам, искусственный интеллект которых развивается в геометрической прогрессии. Они могут «обидеться» всерьез и, признав контент переоптимизированным и бесполезным, отказаться индексировать ресурс вовсе.
Наказание может быть и мягким, заключающимся в потере позиций в выдаче, но в любом случае ничего хорошего в некачественном контенте нет. А ведь пауки интересуются еще и навигацией по сайту (удобна ли она пользователям), оценивают юзабилити, ссылочную массу и др.
Наиболее популярен среди владельцев вопрос об ускорении индексации сайта, но иногда возникает необходимость в обратном: лишить роботов возможности оценивать ресурс (полностью или отдельные части).
Зачем и как закрывать сайт от индексации
Некоторые владельцы ресурсов ошибочно полагают, что индексация происходит по «личному приглашению», которое нужно адресовать ботам, то есть отправить ссылку на ресурс. На самом деле поисковые пауки постоянно обследуют интернет-пространство, так что сайт, не закрытый от индексирования, рано или поздно будет оценен.
Хорошо, если к этому моменту ресурс соответствует требованиям, предъявляемым поисковыми системами. А если нет? Тогда вместо оптимизации можно получить обратный эффект под названием «пессимизация», что в будущем потребует приложения усилий для восстановления реноме.
Объективная необходимость закрыть сайт от индексации полностью может быть вызвана следующими причинами:
-
Ресурс создан недавно, на нем ведутся работы по наполнению, изменению интерфейса и др. До конечного результата еще далеко, и владелец представляет площадку в ином виде, до достижения которого правильнее скрыть ее от поисковых пауков. Аналогичным образом следует поступить и в том случае, если нет возможности заниматься наполнением сайта. Открывать ресурс для аналитической работы пауков лучше после полноценной доработки и настройки. Тогда боты видят современный и актуальный сайт, достойный высокой оценки, и, следовательно, высокого места в выдаче.
-
Существует дубликат ресурса, позволяющий веб-мастерам в реальных условиях испытывать нововведения и возможные изменения. Аналог следует сделать невидимым для роботов, иначе они могут усмотреть дублирование контента, которое влечет крайне неприятные последствия. Если сайт является тестировочной площадкой разрабатываемых скриптов, шаблонов и прочего, он также не должен индексироваться.
-
Если веб-ресурс создается и дорабатывается на хостинге, он доступен в любое время. Это позволяет работать над ним, когда удобно, немедленно воплощать появляющиеся идеи, апробировать разработки. Но лучше делать это в закрытом от роботов режиме, а им отправить ссылку на уже готовый сайт. Пусть они индексируют и отправляют в базу данных готовый ресурс.
Но скрыть от поисковых пауков можно не только сайт полностью, но и отдельные его части (разделы или страницы), индексация которых по определенным причинам нежелательна. Важно ответственно относиться к закрытию страниц ресурса и четко понимать, что далеко не вся информация должна быть доступна роботам и пользователям.
Прежде всего, необходимо скрыть служебную информацию, предназначенную только для владельца и веб-мастеров, работающих с сайтом. Заблокировать для индексации следует дублирующие страницы, содержащие неуникальный контент.
Например, онлайн-магазины с каталогами, насчитывающими не одну сотню страниц, часто страдают от последствий этого. Низкий процент оригинальности будет отмечен и на страницах с личной информацией пользователей, которые также следует запрещать к индексации. Это делается еще и по этическим соображениям. Владельцы справедливо скрывают от поисковых краулеров страницы с корзинами и формами заказов клиентов – смысл они имеют только для конкретного человека, а видеть их в выдаче совсем необязательно. Такую информацию пауки расценивают как «мусорную» и будут признательны, если владелец избавит от необходимости ее индексировать.
Итак, от ботов следует скрывать:
-
служебную информацию;
-
различный «мусор»;
-
дублирующий контент.
К последнему наиболее сурово относится Google, который за большой процент дубляжа может наложить на ресурс санкции. Такие действия системы, мягко говоря, не лучшим образом влияют на дальнейшее продвижение сайта.

Источник: unsplash.com
40 % дубляжа – критический показатель, при котором важно позаботиться о сокрытии страницы от роботов. Главным решением проблемы является создание уникального контента для всех разделов ресурса, но что делать, когда это невозможно?
Примеров масса: законодательные акты, словари, технические характеристики приборов, инструкции к лекарственным препаратам, кулинарные рецепты – сколько ни подбирай синонимов, сделать оригинальным текст об удалении зуба мудрости не получится, как и изложить своими словами нововведение в федеральном законодательстве, если требуются точные формулировки и цитаты из конкретных документов.
Такой контент нужно прятать от поисковых пауков. Если же это невозможно (владельцу необходимо, чтобы страница обязательно присутствовала в выдаче), стоит уповать только на лояльность поисковых систем, с которыми нужно предварительно связаться и пояснить причины плагиата. Хорошо, если есть возможность подчеркнуть смысловую уникальность, когда при большом количестве цитирований текст является оригинальным по смыслу, раскрывает новую мысль или идею, или в нем представлен личный опыт человека.
Как закрыть сайт от индексации с помощью robots.txt
Правильно настроенные допуск/недопуск поисковых роботов к ресурсу или его части являются важными и востребованными аспектами для разработчиков и владельцев. Есть в этой теме решения, ставшие классикой. К их числу, несомненно, относится создание служебного файла robots.txt.
Уже из названия понятно, что файл представляет собой какой-то текст, предназначенный для роботов. Все верно. Остается только пояснить, что «какой-то текст» — это набор директив, позволяющий паукам осуществлять целенаправленную работу по индексированию: они посещают разрешенные страницы и игнорируют запрещенные.
Общение с ресурсом роботы начинают с обращения к robots.txt, предназначенному специально для них. Если файл отсутствует или не содержит указаний для пауков, они приступят к сканированию всех страниц сайта, так как иное не обозначено в документе.
В файле robots.txt закрыть сайт от индексации можно самостоятельно, вовсе не обязательно привлекать для этого специалиста. Представьте или нарисуйте схему своего ресурса: от корня расходятся несколько линий – это пути, ведущие к папкам, страницам, категориям. Определите, какие из них не должны видеть пользователи, получая выдачу на запрос. Теперь поставьте знак STOP перед роботами. Для этого вносятся соответствующие коррективы в robots.txt, содержащий «визитную карточку» робота (User-agent) и собственно запрет (Disallow).
Приступаем:
-
Обозначаете поисковую систему
User-agent: * (все системы)
User-agent: Yandex (для «Яндекса»)
User-agent: Googlebot (для «Гугла»)
Аналогичным образом указывается любой поисковый робот, которых на сегодня известно более трехсот.
-
Вписываете запрещенные к индексированию компоненты
Обратите внимание, что разрешение на сканирование страниц оформляется следующей записью:
Disallow:
При этом запрет выглядит так (для всех страниц):
Disallow: /
Для содержимого одноименной папки:
Disallow: /images/
Для изображений указанного формата: каждый запрещенный к индексации формат вписывается отдельной строкой.
Disallow: *.png
Для документов указанного формата: каждый формат – в отдельной строке.
Disallow: *.doc
Для конкретного файла: каждый файл, который не нужно индексировать, записывается на отдельной строке.
Disallow: /myfile1.htm
Следует крайне внимательно относиться к заполнению инструкции robots.txt, руководствуясь принципом «не навреди», ведь даже мелкий недочет может стать причиной серьезных проблем для ресурса. Количество команд не может превышать отметку в 1024.
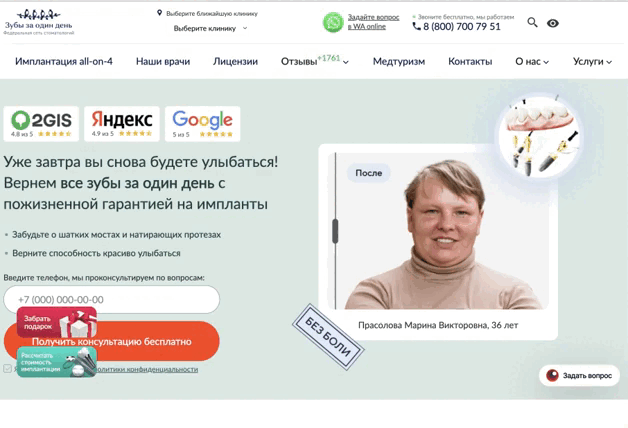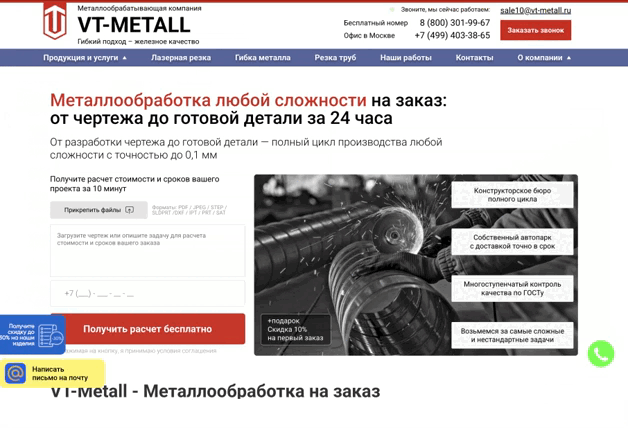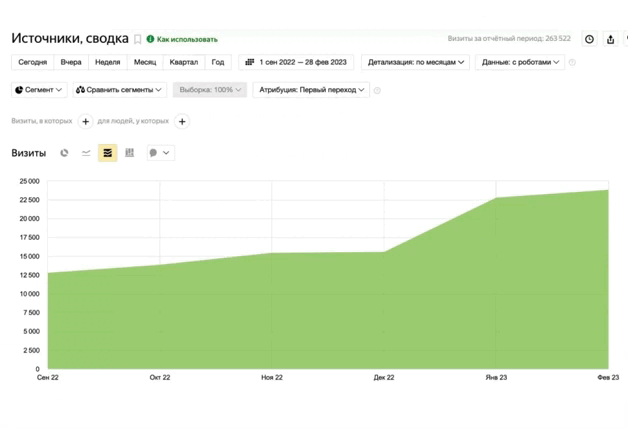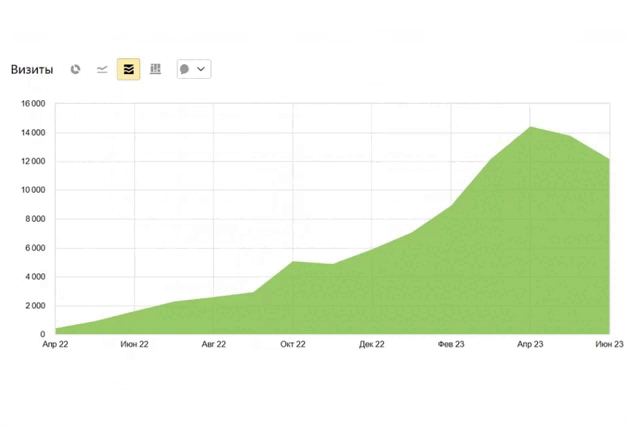
из разных ниш с ростом
от 89% до 1732%

Как закрыть сайт от индексации с помощью мета-тэга
Служебный файл robots.txt, хранящийся в корневом каталоге сайта, позволяет влиять на весь ресурс. Инструментом точечного воздействия является мета-тег robots, разрешающий «спрятать» конкретную страницу ресурса (параметр index) и имеющиеся на ней ссылки (параметр follow). Специалисты отмечают, что Google отдает приоритет именно мета-тегу, считая его запреты и разрешения более авторитетными, чем прописанные в robots.txt.
Мета-тег robots вписывается внутрь HEAD перед <title>.
Параметры index и follow при запрете индексирования предваряет английское «нет» — no, прочитав которое добропорядочные роботы перейдут к следующим страницам, а вот для «воришек» установленные правила законом не являются. С ними нужно бороться другими способами, и это тема отдельной статьи. Пока же задача сводится к грамотному запрещению индексации честным поисковым ботам.
Закрыть страницу и имеющиеся на ней ссылки можно, вписав в код страницы:
<meta name=“robots” content=“noindex,nofollow”>.
Запретить паукам изучать ссылочную массу, оставив саму страницу видимой:
<metaname=“robots” content=“index,nofollow”>.
Ссылки остаются доступными, а страница скрывается от индексирования:
<meta name=“robots” content=“noindex,follow”>.
Эффективнее всего использовать оба инструмента: содружество robots.txt и мета-тега robots позволяет минимизировать риск проведения нежелательного индексирования и указать роботам путь, что существенно ускорит появление ресурса в поисковой базе данных.
Как закрыть сайт от индексации на WordPress
Система контент-менеджмента WordPress привлекает все больше пользователей благодаря своей простоте, удобству и возможности работать с сайтом, не являясь программистом. Не возникнет трудностей и при «игре в прятки» с поисковиками.

Чтобы на «Вордпресс» закрыть сайт от индексации, достаточно активировать одноименную встроенную функцию. Для этого в панели управления нужно следовать по такому пути: «Настройки → Чтение → Видимость» для поисковых систем. Клик в окошке напротив опции (появляется галочка), сохранить изменения. Это первый и самый простой метод.
Можно воспользоваться способом, предполагающим запароливание файлов. Используется функция, имеющаяся в редакторе, Visibility («Видимость»): клик на «Изменить», выбор «Защищено паролем», ввод пароля, клик на Оk. Метод работает, когда нужно скрыть конкретное сообщение или страницу. Если же возникает необходимость спрятать целую категорию, следует воспользоваться одним из плагинов. Из представленного многообразия лучше выбрать свежую версию, но в остальном все зависит от предпочтений пользователя.
Как закрыть сайт от индексации посредством файла htaccess
Иногда роботы игнорируют данные им рекомендации не сканировать сайт, не обращают внимания на пароли. В таком случае приходится прибегать к глубинным изменениям, касающимся серверных настроек. Главным героем становится файл .htacces, куда вписываются определенные коды, позволяющие ресурсу сказать краулерам: «Стоп!».
-
Способ 1
В файл .htaccess вписываем следующий код:
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
SetEnvIfNoCase User-Agent "^Aport" search_bot
SetEnvIfNoCase User-Agent "^msnbot" search_bot
SetEnvIfNoCase User-Agent "^spider" search_bot
SetEnvIfNoCase User-Agent "^Robot" search_bot
SetEnvIfNoCase User-Agent "^php" search_bot
SetEnvIfNoCase User-Agent "^Mail" search_bot
SetEnvIfNoCase User-Agent "^bot" search_bot
SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot
SetEnvIfNoCase User-Agent "^Snapbot" search_bot
SetEnvIfNoCase User-Agent "^WordPress" search_bot
SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot
SetEnvIfNoCase User-Agent "^Parser" search_bot.
Запрет боту каждой поисковой системы прописывается отдельной строкой. Ознакомившись со специальным кодом, пауки понимают, что сайт закрыт от индексации, и переходят на другой ресурс.
-
Способ 2
Прописать в файле .htaccess ответ сервера для каждой страницы, которую необходимо скрыть:
Ответ сервера – 403. Доступ к ресурсу запрещен — код 403 Forbidden.
Либо:
Ответ сервера — 410. Ресурс недоступен — окончательно удален.
-
Способ 3
Пароль на запрет индексации предполагает введение в файл .htaccess следующего кода:
AuthType Basic
AuthName "Password Protected Area"
AuthUserFile /home/user/www-auth/.htpasswd
Require valid-user
home/user/www-auth/.htpasswd.
Пароль задается владельцем сайта, которому также следует обозначить себя в коде, добавив имя пользователя (UserName):
htpasswd -c /home/user/www-auth/.htpasswd UserName.
Как закрыть от индексации определенные элементы на страницах сайта
-
SEO-тег <noindex>
Альтернативный вариант атрибута nofollow, придуман сотрудниками «Яндекса», не используется в официальной спецификации html, выглядит так:
<!—noindex—>Любая часть страницы сайта: код, текст, который нужно закрыть от индексации<!—/noindex—>.
Не нужно путать сеошный тег с одноименным мета-тегом, прописываемым в файле robots.txt и запрещающим ботам сканирование всей страницы. SEO-тег <noindex> означает запрет на индексацию части кода.
Что можно спрятать благодаря использованию SEO-тега <noindex>:
-
неуникальный, дублирующий, динамичный текстовый контент;
-
счетчики и баннеры;
-
формы подписки на рассылку;
-
различный «мусорный» текст.
Многие веб-мастера продолжают пользоваться названным тегом, не меньшее количество программистов считают, что он изжил себя, относят его к инструменту так называемой серой оптимизации и предпочитают использование атрибута, описание которого приведено ниже.
-
Атрибут rel=»nofollow»
О важности ссылочной массы для любого ресурса можно говорить долго, но важно понимать, что неграмотное использование инструмента приводит к негативным последствиям в виде понижения в выдаче и потери сайтом «весомости», поскольку вес страницы, имеющей внешнюю ссылку, делится с тем самым сторонним ресурсом, на который ссылается сайт. Конечно, обидно. Чтобы не допустить неоправданного разделения веса, можно запретить роботам индексацию некоторых ссылок. В таком случае они не станут учитывать вес ссылки на сторонний ресурс. Помогает в этом атрибут rel=»nofollow».
Если есть уверенность, что размещенные ссылки ведут на качественные интересные ресурсы, никаких проблем не возникнет. Но часто подписчики и разовые посетители сайта оставляют в комментариях ссылки на веб-площадки, которые вам даже не знакомы. Роботы не сортируют ссылки на «свои/чужие» и индексирует все.
Итак, использование атрибута rel=»nofollow» тега <a> оправданно, если требуется:
-
Запретить индексацию ссылок, оставляемых пользователями.
-
Скрыть от роботов рекламные и бартерные ссылки.
-
Не делиться весом с популярным ресурсом, ссылка на который необходима.
-
Обозначить приоритетные направления для поисковых роботов (закрыть все ненужное, сделав работу пауков целенаправленной).
Важно, чтобы внешних ссылок не было слишком много во избежание проблем с индексацией и ранжированием, но и запретов должны использоваться умеренно, поскольку искусственный интеллект сразу начинает подозревать неладное в большом объеме «секретов».
-
SEOhide
Еще один метод сокрытия контента и ссылок от поисковиков с помощью JavaScript: в коде страницы элементы скрываются, а пользователям остаются доступны.
При этом некоторые эксперты склонны рассматривать SEOhide как «черный» метод продвижения, поскольку поисковые пауки и посетители видят разные версии контента. Отсюда один из главных минусов технологии – угроза попасть под санкции за клоакинг.
Другие веб-мастера апеллируют к тому, что невозможность прочитать «Яваскрипт» – проблема поискового робота, а вовсе не программистов, поэтому санкции к сайту из-за обвинений в клоакинге применяться не могут. К тому же близок тот час, когда поисковые роботы научатся полноценно распознавать шифры JavaScript.
Что касается преимуществ технологии SEOhide, к их числу относятся:
-
неограниченность в использовании для всех поисковиков;
-
корректное распределение ссылочного веса;
-
возможность уменьшить заспамленность текста;
-
доказанная эффективность использования онлайн-магазинами, чьи каталоги могут занимать несколько сотен страниц.

Как проверить, закрыты ли определенные страницы сайта от индексации
Чтобы выяснить, как индексируются структурные части ресурса, можно использовать разные методы.
-
Специальные сервисы поисковых систем
-
Поисковые операторы
-
Плагины и расширения
-
Спецсервисы
В «Яндекс.Вебмастер» алгоритм следующий:
Авторизация в сервисе — меню «Индексирование сайта» — «Страницы в поиске».

Либо «Индексирование сайта – История – Страницы в поиске».
В Google Webmaster Tools двигаться нужно по такому пути: «Панель управления – Search Console – Индекс Google – Статус индексирования».
Добавив к запросу определенные символы, получим массу полезной информации о ресурсе. Так, введя в поисковике «site: адрес_вашего_сайта», можно убедиться в количестве проиндексированных страниц.

Каждая система обладает своим набором операторов, позволяющих уточнить разные параметры. При этом важно обратить внимание на результаты, выдаваемые Google и «Яндекс». Они должны быть если не идентичны, то максимально схожи. Если же наблюдаются существенные отличия, стоит проверить сайт на наличие проблем со структурой, индексацией, возможными санкциями.
Использование специализированных программ позволяет автоматизировать процесс проверки индексации сайта.

RDS bar, доступный для скачивания в любом браузере, остается на пике популярности среди плагинов.
Программные модули представлены в бесплатных и коммерческих вариантах, так что выбор остается за владельцем ресурса.
Чтобы получить объективные данные индексации, программисты предпочитают использовать специальные сервисы, которые позволяют не только узнавать количество страниц ресурса в выдаче, но и видеть их.
Сервисов-помощников масса. Они могут быть доступны бесплатно или требовать внесение определенной суммы. К примеру, на сервисе «Серпхант» () доступна проверка 50 страниц за 24 часа, а дальнейшие будут платными.

Платный сервис Topvisor требует 24 копейки за проверку каждой полосы, но качество его работы стоит затраченных средств.

Сервис точно определит, какие страницы ресурса находятся в базе поисковиков, а какие исключены из нее.
Основные ошибки при закрытии от индексации отдельных элементов сайта
При оформлении запрета на индексацию требуется предельное внимание и сосредоточенность, ведь даже самые мелкие ошибки становятся причиной больших проблем, на устранение которых требуется достаточно времени. Лучше сразу выполнить все действия точно и получить искомый результат, а не заработать лишнюю головную боль.
Виды ошибок:
-
Забыли отменить запрет индексации в CMS
Об опции «не индексировать сайт» разработчики часто забывают, «сырой» ресурс становится достоянием общественности, что, конечно, не способствует повышению его рейтинга. Некоторые системы управления контентом (CMS), заботясь о пользователях, создающих сайты и работающих над ними, самостоятельно делают активным параметр запрета индексации. Но когда деятельность завершена, далеко не все мастера вспоминают о необходимости снять галочку напротив запрета.
-
Допустили синтаксические ошибки
Проверка синтаксиса в файле robots.txt и тегах после их изменения должна стать хорошей привычкой, которая позволяет избежать негативных последствий ошибки в кодах.
Стоит использовать валидаторы, помогающие обнаружить синтаксические ошибки и вовремя исправить их.
-
Использовали маски некорректно
Кажущаяся простота и доступность инструмента заставляют многих «мастеров» пользоваться масками, где надо и, в общем-то, не надо. Если она написана правильно, то становится действительно мощным орудием, позволяющим не только добавить сайту зрелищности, но и скрыть часть контента в интересах владельца. Неправильное написание маски может привести к тому, что скрытой окажется не часть страницы, а несколько разделов! Найти адекватный онлайн-сервис для проверки правильности маски сложно, а потому лучше доверить ее написание настоящим профессионалам.














