





 Оставить комментарий
Оставить комментарий
В статье рассказывается:
- Что такое парсинг данных в интернете
- Этапы парсинга данных с сайта
- 9 лучших доступных инструментов для парсинга данных сайта
- ТОП-6 самых мощных парсеров данных сайта для разных нужд
- Парсинг данных сайта с помощью функции importxml в таблицах Google
- Насколько законно парсить данные с сайтов
- Правовое регулирование парсинга данных в Интернете в России
- Как защитить свой сайт от парсинга данных
В статье мы расскажем, что такое парсинг сайтов (web scraping), который используется для решения абсолютно разных задач. Например, парсинг позволяет собирать новости из разных источников, создавая сводки, наполнять базу e-mail адресов или сравнивать стоимость товара в интернет-магазинах. Парсинговые инструменты подходят и для технического анализа сайта.
Что такое парсинг данных в интернете
Под парсингом понимают процесс проведения специальной программой или скриптом синтаксического анализа сайтов. Собранные данные выдаются в заданном формате, по определенным правилам и алгоритмам. Парсинг данных с сайта выполняется на одном из языков программирования.

Источник: shutterstock.com
С его помощью данные могут быть собраны из справочника, интернет-магазина, блога, форума и с любой другой интернет-площадки.
Парсинг — наиболее оптимальный инструмент автоматизации процесса сбора и хранения информации с сайтов. Прекрасно подходит для создания и обновления площадок, схожих по оформлению, наполнению и структуре.
Инструмент позволяет получить исходный код страницы. Парсер проходит по нему, как по обычным словам, и выявляет определенные соответствия, записанные в программный код. Затем сравнивает, сопоставляет и сохраняет то, что необходимо, по заданным правилам в удобном для вас формате. Например, определенные скрипты и программы остаются в SQL, какие-то — в XML, а что-то — в TXT или Excel.
Что парсят? Абсолютно все. В зависимости от того, что используете, и степени защиты сайта или другой интернет-площадки. Есть лишь одно ограничение — ваша фантазия.
Зачем нужен парсинг данных сайта
Используя инструменты web scraping (парсинг), можно извлекать и собирать любые открытые данные с сайтов. Эти инструменты выручают при необходимости быстрого сбора и сохранения в удобном формате любой информации из интернета. Парсинг данных с сайта — это инновационный способ получения сведений, при котором не нужно повторно вводить данные вручную или делать копипаст.

Источник: shutterstock.com
Такое ПО предназначено для поиска сведений как в автоматическом режиме, так и под контролем пользователя. Парсер выбирает новую или обновленную информацию и сохраняет ее в удобном виде, обеспечивая быстрый доступ к ней.
5 примеров, когда парсинг может помочь:
Сбор информации для анализа рыночной среды
Извлечение контактных данных
Разработка решений по загрузке с StackOverflow
Поиск вакансий или персонала
Мониторинг цен в разных магазинах
Благодаря специальным сервисам извлечения данных можно отслеживать направление развития предприятия или отрасли в течение ближайшего полугода, обеспечивая тем самым мощное подспорье для оценки рынка. Парсер получает сведения от множества провайдеров, специализация которых — анализ информации, а также компаний, исследующих рынок, после чего собирает эти данные в единое место для референции.
Если необходим сбор и систематизация почтовых адресов, контактных данных с разных сайтов и из соцсетей, также используюся парсинговые инструменты. Они помогают формировать удобные списки для бизнеса: информацию о покупателях, поставщиках, производителях.
Парсинговые инструменты подходят для создания решений применения и хранения в оффлайн-среде данных с множества сайтов (в том числе, StackOverflow). Благодаря этому, вы не зависите от интернет-соединения. Обеспечиваете доступ к сведениям вне зависимости от подключения к сети.
Парсинг данных с сайта — незаменимый инструмент для работодателя, находящегося в активном поиске персонала для предприятия, а также для человека, который подбирает вакантное место. При помощи парсинга можно настроить выборку информации на основе разных имеющихся фильтров и получать данные без утомительного ручного поиска.
Парсинг пригодится и тем, кто активно делает покупки в интернете, изучает цены, ищет товары сразу в нескольких магазинах.
Допустим, вы владеете интернет-магазином бижутерии, и необходимо быстро собрать информацию о конкурентах. Задача — получить данные с карточек товаров, чтобы оценить, как они их заполняют и насколько лучше это делают. Важно определить, сведения с каких интернет-площадок необходимы, выбрать программу или скрипт для парсинга текста и запустить. В одном файле парсер соберет все сведения, допустим, наименование, стоимость, категорию и описание продукта, что позволит проанализировать полученные данные и понять, какую ценовую политику вести.
А что, если требуется изучить обратную связь от покупателей? Эту задачу также позволяет решить парсинг сайта, помогая собрать нужные данные воедино и прочесть отзывы клиентов о конкуренте.
Этапы парсинга данных с сайта
Сбор контента
Как правило, в сервис для парсинга загружают код страницы сайта, с которым уже работает специальный скрипт. Он делит весь код на лексемы, оценивает, какие сведения нужны пользователю.
Извлечение данных
Посетитель не нуждается во всем контенте, который есть на странице. Опять же в качестве примера приведем интернет-магазин бижутерии. Нам необходимы только отзывы покупателей под определенными товарными единицами. Парсер найдет в коде страницы место с указанием категории товара «Бижутерия». Затем определит, где именно расположены отзывы, и сформирует файл исключительно с текстами комментариев.
Сохранение результатов
После извлечения необходимых данных с сайтов их нужно сохранить. Как правило, такие сведения заносят в таблицы, чтобы видеть наглядно. Можно заносить информацию в базу данных. В этом случае аналитик выбирает наиболее удобный вариант.
Парсинг обладает как преимуществами, так и недостатками. Он помогает изучить текстовый контент в большом объеме. Но при этом вы не застрахованы, что кто-то проанализирует и украдет данные, извлечет конфиденциальные сведения.
9 лучших доступных инструментов для парсинга данных сайта
Webhose.io
Scrapinghub
VisualScraper
80legs
OutWit Hub
Import.io
Dexi.io
ParseHub
Spinn3r

Webhose.io позволяет напрямую в онлайн-режиме выходить к структурированной информации, полученной после парсинга многочисленных интернет-площадок. Программа собирает web-данные на более 240 языках, сохраняя результаты в разных форматах, в том числе XML, JSON и RSS.
Webhose.io представляет собой web-приложение для браузера. Парсит данные по собственной уникальной технологии, позволяющей анализировать сведения в огромных объемах из множества источников с единственным API. Вы можете пользоваться бесплатным тарифным планом и ежемесячно обрабатывать тысячу запросов. Также предусмотрена платная премиум-версия: за $50 можно обрабатывать 5 тысяч запросов в месяц.

Scrapinghub – облачная программа для парсинга, с помощью которой можно искать и отбирать необходимую для любых целей информацию. Scrapinghub использует Crawlera, умный прокси-ротатор с функциями обхода защиты от ботов. Программа умеет работать с огромными пластами информации и интернет-площадками, защищенными от роботов.
Scrapinghub способна преобразовывать веб-страницы в структурированный контент. Группа профессионалов гарантирует индивидуальный подход к каждому клиенту и обещает создать решение под любой уникальный случай. При использовании базового бесплатного тарифа вам становится доступен один поисковый робот (обработка до 1 Гб информации, потом — $9 ежемесячно). При покупке премиального тарифа предоставляются 4 пакета параллельных поисковых ботов.

VisualScraper – еще одно программное обеспечение, позволяющее парсить большие пласты информации в интернете. VisualScraper собирает сведения с нескольких web-страниц и синтезирует результаты в онлайн-режиме. Помимо этого, предусмотрена возможность экспорта информации в форматы CSV, XML, JSON и SQL.
Использовать web-данные и управлять ими можно с помощью простого интерфейса типа point and click.
Минимальная стоимость платного пакета VisualScraper, позволяющего обрабатывать свыше 100 тысяч страниц ежемесячно, составляет $49. Существует бесплатная версия, похожая на Parsehub. Доступна для Windows и предоставляет возможность использовать дополнительные функции за деньги.

80legs – это мощная и гибкая программа, позволяющая парсить данные с сайтов. Преимущество в том, что ее легко адаптировать под требования пользователя. Сервис обрабатывает огромные объемы данных и моментально их извлекает. 80legs используют такие всемирно известные компании, как MailChimp и PayPal.
Сервис оснащен опцией Datafiniti для сверхбыстрого поиска данных. Благодаря ей, программа буквально за секунды извлекает необходимую информацию с сайтов.
Есть бесплатный тариф, позволяющий выбирать 10 тысяч ссылок за сессию. Стоимость коммерческого пакета составляет $29 в месяц — 100 тысяч ссылок за сессию.

OutWit Hub – дополнительный инструмент к Firefox, где предусмотрены десятки функций для извлечения информации в удобном формате. Программа обладает простым интерфейсом, позволяющим извлекать малые или большие объемы данных, если требуется.
OutWit дает возможность вычленять любые web-страницы прямо из браузера и создавать в панели с настройками автоматические агенты, извлекающие и сохраняющие информацию в необходимом формате. Это одна из самых простых программ по сбору данных. Она бесплатна и не требует особых навыков в создании кодов.

Import.io позволяет просто и быстро создавать пакеты информации: нужно лишь интегрировать данные с определенной web-страницы и экспортировать их в CVS. У вас есть возможность за минуту формировать тысячи API в соответствии со своими требованиями, без единой кодовой строки.
Чтобы собрать огромный объем необходимых сведений, программа применяет новые технологии, причем недорого. Можно пользоваться и доступными бесплатными приложениями для Windows, Mac OS X и Linux, чтобы создавать экстракторы данных и поисковых роботов, которые будут загружать информацию и синхронизировать с учетной записью в онлайн-режиме.

Dexi.io парсит данные с любого сайта. При этом не нужно загружать дополнительные приложения, как и в случае с Webhose. Сервис сам ставит поисковых роботов и извлекает информацию в онлайн-режиме. Вы можете сохранять собранные данные в облаке, к примеру, в Google Drive и Box.net, или экспортировать их в форматах CSV и JSON.
Программа позволяет анонимно просматривать информацию. Предлагает прокси-серверы, помогающие скрыть идентификационные сведения пользователя. Сохраняет данные у себя на серверах в течение двух недель с последующей архивацией.
Бесплатно пользоваться сервисом можно в течение 20 часов. Далее ежемесячная цена составляет $29.
Может парсить данные с одного или множества сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Программа пользуется технологией самообучения, за счет чего распознает самую сложную документацию в интернете, а затем создает выходной файл в нужном вам формате.
ParseHub — это самостоятельный инструмент рабочего стола для Windows, Mac OS X и Linux, отделенный от web-приложения. Сервис предоставляет пять бесплатных тестовых проектов для парсинга.
Стоимость тарифа «Премиум» составляет $89. Позволяет обрабатывать 20 проектов и 10 тысяч web-страниц за проект.

Spinn3r дает возможность парсить информацию из таких источников, как блоги, новостные порталы, каналы RSS и Atom, соцсети. У Spinn3r обновляемый API, выполняющий 95 % работы по индексации. Обладает улучшенной защитой от спама и повышенной степенью безопасности информации.
Spinn3r индексирует содержание страниц, как Google, и сохраняет извлеченную информацию в файлах в формате JSON. Сервис непрерывно мониторит интернет-сайты, находит обновленные необходимые данные из многочисленных источников, что дает пользователю возможность всегда получать актуальные сведения в режиме онлайн. Консоль администрирования позволяет управлять анализом. Предусмотрен полнотекстовый поиск.
ТОП-6 самых мощных парсеров данных сайта для разных нужд
Технически проанализировать сайт нельзя. Автоматизированный сервис помогает найти большую часть погрешностей, битые ссылки, некорректные редиректы, понять, правильно ли настроен robots.txt, узнать степень вложенности и получить другую важную информацию.
Программ для парсинга данных с сайтов множество. У них разный функционал, степень удобства и, конечно, разная стоимость.
Приведем 5 самых востребованных сервисов, позволяющих выполнять парсинг данных с сайта, и проверим, насколько они удобны и оперативны.
Чтобы оценить функционал, рассмотрим, что непременно должна уметь идеальная программа для парсинга:
Искать битые ссылки
Указывать входящие и исходящие ссылки страницы
Обозначать тип и цепочку редиректов
Уметь фильтровать страницы:
пользоваться регулярными выражениями;
сканировать по правилам robots.txt, meta robots, canonical и т. д.
Парсить отдельные ссылки
Выявлять дубли Title, Description и заголовки H
Указывать степень вложенности
Указывать заголовки Н и их количество
Указывать код ответа сервера
Уметь менять User Agent
Указывать Title и его длину
Description и его длину
Keywords и его длину
Canonical
Meta robots
Указывать Alt и его длину
Обозначать тип контента
Таким образом, у нас получилось 17 главных требований. В отдельном порядке будем учитывать наличие дополнительных функций, а также удобство сервиса в использовании и темп его работы.
Для определения скорости рассмотрим сайт, в котором порядка шести тысяч страниц. При этом к индексации разрешено примерно 1500 (заметим, что у ресурса открыты скрипты, а потому он может парсить их тоже). Для каждой программы условия парсинга будут одинаковыми.
1. Xenu’s Link Sleuth

Помогает искать битые ссылки, поэтому функции значительно отличаются от большей части приведенных ниже сервисов. Программа бесплатна, что является большим преимуществом.
Свою основную задачу она решает прекрасно, хотя есть недостаток: не обозначает ссылки со страницы и на страницу. Проводить подробный анализ с ее помощью не получится. Но если необходимо узнать о наличии битых ссылок на сайте и уровне вложенности страниц, используйте именно Xenu’s Link Sleuth.
Когда необходимо получить больше сведений о сайте, отдайте предпочтение другому парсеру.
На парсинг сайта ушло 17:59 минут. Не так оперативно, как хотелось, но вполне нормально.
Оценка: 8 баллов.
2. WildShark SEO Spider
WildShark SEO Spider – бесплатная западная программа. Очень простая и удобная в использовании. Функционал шире, чем у Xenu’s Link Sleuth, но функций недостаточно. С помощью сервиса можно быстро определить, в каком техническом состоянии находится сайт. Чтобы выполнить более тщательный анализ, потребуется другая программа.
Отличительная черта — наличие подсказок в правой части экрана, где всплывает ошибка и общие сведения о ней. Кроме того, сервис может выполнять парсинг OG микроразметки. Это достаточно редкая функция, которая встречается нечасто.
Парсинг данных с сайта занял 9 минут. Учитывая, что программа бесплатная, это прекрасный показатель.
Оценка: 9,5 баллов.
3. ComparseR 1.0.129
Достойный сервис, который превосходно парсит данные с сайтов. Предназначен для проверки индексации в поисковиках. У программы достаточно функций. Не хватает лишь перечня ссылок на страницу и с нее.
Дополнительные функции:
Проверяет индексацию страниц в Google и «Яндекс» (показывает страницы, проиндексированные в ПС, и даже те, которые прошли через фильтр для парсинга).
Позволяет просматривать структуру сайта.
Ищет код или текст на страницах.
Генерирует Sitemap.
Может парсить многостраничные сайты.
Парсит сайты, предполагающие авторизацию.
Проверяет индексацию сайта при заполнении robots.txt.
Функционал можно уверенно назвать неплохим. Простая и удобная программа, с которой легко работать.
На парсинг ушло 2:56. Это отличный показатель.
Оценка: 16,5 баллов.
4. Majento SiteAnalayzer 1.4.4.91

Majento SiteAnalayzer 1.4.4.91 – неплохая удобная российская программа. Пользоваться можно бесплатно. Функционал лучше, если сравнивать с западными аналогами. Но при этом у сервиса два недостатка:
Медленно работает.
Скрывает количество заголовков Н.
Многие эксперты считают Majento SiteAnalayzer 1.4.4.91 хорошей альтернативой платным программам. Инструмент помогает тщательно проверить сайт и узнать необходимые данные.
Дополнительный функционал не очень широк, но все же имеется.
Majento SiteAnalayzer 1.4.4.91 позволяет:
Генерировать Sitemap.
Просматривать структуру сайта.
Видеть визуальное оформление сниппета в Google.
Работает сервис довольно медленно. На парсинг ушло 29:14 минут. Благодаря функционалу минус не столь заметен. Сервис бесплатный.
Оценка: 16,5 баллов.
5. Screaming Frog SEO Spider 9.2.
Screaming Frog – британская программа, позволяющая выполнять парсинг данных с сайта. Один из лучших сервисов среди аналогов. Недочеты: высокая стоимость и не очень удобный интерфейс.
Программа позволяет собирать довольно много показателей. У нее есть все обязательные для парсера программы.
Заметим, Screaming Frog обладает обширным мануалом по работе с парсингом. В нем содержатся все необходимые сведения.
Сервис довольно удобен. Очень легко поверхностно просмотреть информацию, но для более детального анализа необходимо исследовать мануал.
У программы немало дополнительных функций. Самые интересные из них:
Проверяет заполнение robots.txt, и как от этого зависит индексация сайта.
Просматривает структуру сайта.
Сканирует сайты, предполагающие авторизацию.
Генерирует Sitemap.
Ищет по коду.
Настраивает скорость парсинга сайта.
На парсинг ушло 3 минуты. Отличная скорость.
Оценка: 17 баллов.
6. Netpeak Spider 3.0

Netpeak Spider 3.0 представляет собой новую версию программы для парсинга, которая появилась недавно. Как и Screaming Frog, проводит качественный парсинг данных с сайта. Отличается удобным и понятным интерфейсом на русском языке и наличием дополнительного функционала.
По словам разработчиков Netpeak Spider 3.0, программа парсит большие сайты, минимально затрачивая ресурсы компьютера. Полезная характеристика, поскольку не каждый сервис справляется с ресурсами-миллионниками. Для парсинга таких крупных площадок зачастую используют виртуальные машины с усовершенствованными характеристиками, а это лишние затраты.
Netpeak Spider 3.0 обладает всем обязательным функционалом, что вполне естественно при его стоимости.
Из минусов отметим не очень удачный блок ошибок. Непонятно, по какому принципу они классифицируются, и почему не предусмотрено деление по типу.
Отличительные характеристики сервиса:
Удобная настройка фильтров.
Наличие простого и интерактивного интерфейса.
Возможность выгрузки отдельных отчетов.
Получение информации по определенной ссылке без лишних кликов.
Просмотр структуры сайта.
Возможность задать пользовательский robots.txt для сканирования.
Парсинг сайтов, предполагающих авторизацию.
Поиск кода или текстового контента на страницах сайта.
Возможность настроить скорость парсинга.
Приостановка и продолжение парсинга в любое время.
Возможность перенести данные по проекту на другой ПК.
Парсинг данных с сайта занял 5 минут, что является очень хорошим показателем.
Оценка: 17 баллов.
Сравнение разных парсеров (таблица):

Парсинг данных сайта с помощью функции importxml в таблицах Google
Парсинг HTML — это выборочное извлечение данных в большом объеме с других сайтов с последующим их использованием.
При помощи программы автоматически выделяем и импортируем повторяющуюся информацию, чем существенно экономим время и избегаем вероятных ошибок при ручном копировании.
Допустим, нужно узнать расстояние по прямой между двумя заданными точками во множестве значений. Вводим города попарно и налаживаем автоматический импорт расстояний. Для этого воспользуемся:
таблицей Google Docs;
несколькими базовыми выражениями на xPath для формулы importxml.
Находим сайт с необходимыми данными, после чего вводим названия городов. Показатель расстояния появится в ячейке таблицы № 3. Как спарсить часть сведений в таблицу Google? Применить importxml.
Правой кнопкой мыши кликнуть по заголовку, где указано расстояние, и выбрать «Просмотр кода элемента». Необходимую строчку увидим в html-тэге h1.

Проверить адрес страницы: он выглядит соответственно (http://marshrut.su/rasstojanie/mezhdu-gorodami/mezhdu-gorodami?ot=Астана&do=Варшава).
Сформировать URL, используя оператор «concatenate», чтобы склеить части адреса и введенные города.
=concatenate("http://marshrut.su/rasstojanie/mezhdu-gorodami/?ot=";A3;"&do=";B3)
Применить importxml. Первым аргументом станет concatenate (формируемый URL), вторым — простое выражение на xPath — //h1. Итак, обозначили необходимость парсинга всех заголовков h1 в ячейку таблицы. Нам улыбнулась удача — название встречается один раз на странице, что избавляет от обработки большого пласта информации.
=importxml(concatenate("http://marshrut.su/rasstojanie/mezhdu-gorodami/?ot=";A3;"&do=";B3); "//h1")
И, наконец, программа выдает строчку «Расстояние от… до… км». Нужно обрезать все лишнее при помощи mid. Чтобы вычислить, какую часть отрезка сократить, определяем длину наименований городов при помощи len, после чего суммируем с размером других слов. Итоговая формула выглядит так:
=mid(importxml(concatenate("http://marshrut.su/rasstojanie/mezhdu-gorodami/?ot=";A3;"&do=";B3); "//h1");len(B3)+len(A3)+19;10)
Сейчас можно ввести неограниченное количество пар городов, «вытянуть» ячейку C2 вниз и сразу же получить значения всех расстояний между населенными пунктами.

из разных ниш с ростом
от 89% до 1732%
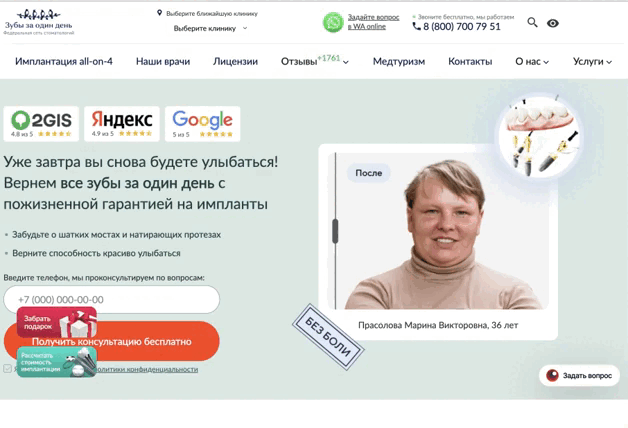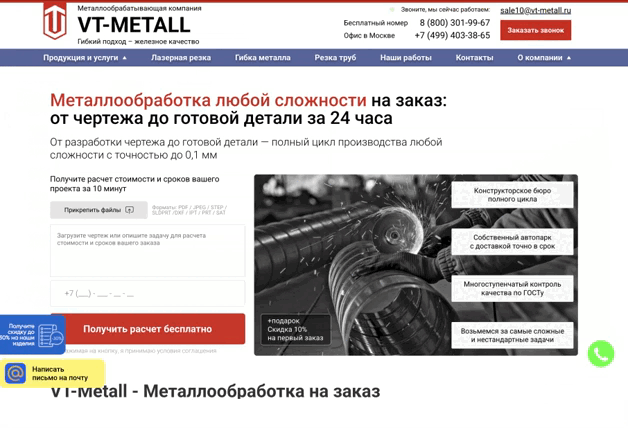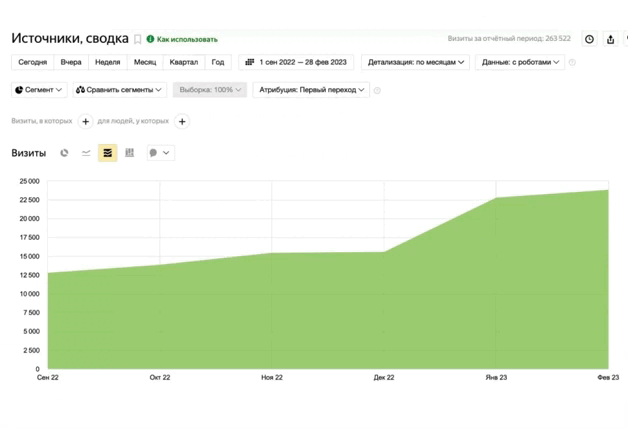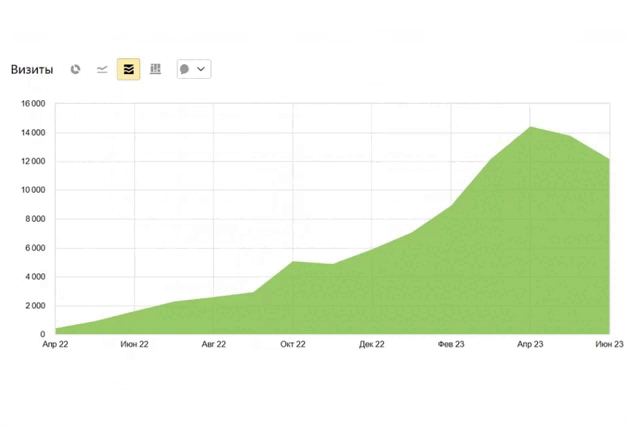

Насколько законно парсить данные с сайтов
Является ли парсер одним из самых незаменимых IT-сервисов для сбора информации? Или это капкан, попадание в который связано с неизбежным нарушением законодательства? Парсинг данных с сайтов вполне мог бы превратиться в один из инновационных инструментов сбора контента по всему интернету, если бы не такой нюанс: юридически очень трудно изучить этот метод.
Парсинг данных с сайта — процедура, в ходе которой ПО автоматически извлекает информацию с web-ресурса и «прочесывает» множество страниц. Такие поисковики, как Google и Bing, решают аналогичные задачи при индексации web-страниц. При парсинге же идет более углубленная работа: автоматизированные механизмы преобразуют данные в формат, позволяющий в будущем использовать их, заносить в базы или электронные таблицы.

Источник: shutterstock.com
Парсинг данных с сайта — не синоним API. Допустим, предприятие может открыть доступ к API, чтобы другие системы могли использовать его информацию. Но данные будут не особо качественными и в гораздо меньшем количестве. Парсинг предоставляет более актуальные сведения, чем API, и намного легче настраивается с позиции структуры.
Данные, полученные посредством парсинга, использовуют в разных сферах. Например, спортивному обозревателю удобно получать статистику по футбольным матчам для своего материала. Владельцу интернет-магазина — извлекать названия товарных единиц и стоимости из разных источников, чтобы впоследствии анализировать.
Несмотря на то, что парсинг высокоэффективен, зачастую возникают сложности с юридической точки зрения. Так как при парсинге присваивается конфиденциальная информация из различных источников, появляются трудности этического и правового характера.
В области парсинга не существует четких юридических границ, ситуация постоянно меняется. Однако примерно обозначить наиболее рискованные зоны можно.
Реальные примеры судебных разбирательств, связанных с парсингом данных с сайтов, ставшие прецедентами.

Источник: shutterstock.com
2000-2009: eBay
После того как появился парсинг данных с сайта, достаточно долго не возникало правовых разбирательств. Но в 2000 году использование способа вызвало настоящую войну: eBay выступил против компании, которая собирала аукционные данные Bidder’s Edge. Компания eBay обвинила Bidder’s Edge в том, что последняя незаконно извлекала информацию, и, в подтверждение своих слов, приводила Доктрину о нарушении границ движимого имущества. Суд удовлетворил исковое заявление, отметив, что активный парсинг способен навредить деятельности eBay.
Но в 2003 году в ходе судебного процесса Intel против Hamidi калифорнийский Верховный суд отклонил обоснование, используемое eBay против Bidder’s Edge, и постановил, что Доктрина о нарушении границ движимого имущества не распространяется на компьютерную сферу, если личной собственности не был причинен реальный ущерб.
Самые ранние разбирательства против парсинга опирались на Доктрину о нарушении границ движимого имущества, и побеждали в них истцы. Но сейчас такая схема не действует.
2009: Facebook*
В 2009 году Facebook* подал в суд на Power.com – интернет-ресурс, объединявший разные соцсети в одну централизованную площадку. Поводом для иска послужило то, что сервис включил Facebook* в свою площадку. Так как Power.com парсил контент Facebook*, преступая установленные границы, истец заявил о нарушении авторского права. Facebook* обвинил Power.com в том, что последний копирует сайт, извлекая данные о пользователях.
По мнению обвинителя, процедура и прямо, и косвенно нарушала авторское право. Суд принял позицию Facebook*, и с этого момента решения, связанные с законностью парсинга, стали принимать в пользу авторов контента сайтов.
Даже если сервис не парсит контрафактную информацию, собирая общедоступные данные, процедура может считаться нарушением авторских прав. Это связано с тем, что программа копирует информацию, которая с технической точки зрения считается контрафактной.
2011-2014: Ауэрнхаймер
В 2010 году хакер Эндрю Ауэрнхаймер обнаружил слабое место в системе защиты на сайте AT&T и при помощи парсинга получил e-mail пользователей, посещавших интернет-ресурсы с Айпадов. Обернув себе на пользу недоработку в системе, Ауэрнхаймер получил доступ к тысячам почтовых адресов. Суд постановил, что Эндрю несанкционированно проник на сервер AT&T и присвоил чужую информацию, в связи с чем счел его виновным.
Даже если конфиденциальные данные номинально общедоступны, извлекать их с помощью парсинга рискованно с юридической точки зрения. Конечно, можно постараться доказать в суде, что вы не взламывали ни коды, ни пароли, чтобы получить данные. Но, как бы то ни было, это опасно.
2013: Meltwater
Meltwater – компания, специализирующаяся на разработке ПО. Один из ее продуктов, Global Media Monitoring, делает парсинг данных с сайта, чтобы собирать новости. Ассошиэйтед Пресс подала в суд исковое заявление, так как Meltwater парсила новости, защищенные авторским правом, а также неправомерно присваивала материалы. Суд постановил, что копирование статей и авторского изложения фактов противоречит законодательным нормам. Помимо этого, компания Meltwater использовала статьи, не соблюдая установленные стандарты. Далеко не во всех случаях авторские материалы можно парсить.
2014: QVC
В 2014 году состоялось судебное разбирательство между популярным ТВ-ритейлером QVC и приложением-магазином Resultly. Поводом послужило обвинение QVC оппонента в «чрезмерном парсинге». Ритейлер заявлял, что Resultly маскировала своих поисковых роботов с целью сокрытия исходного IP-адреса, что мешало блокировке QVC нежелательных парсинговых сервисов.
Довольно сильная агрессия ботов к серверам QVC вызвала перегрузку, повлекшую за собой отключение электричества. Сумма нанесенного ущерба составила 2 миллиона долларов. Суд принял сторону Resultly и оправдал компанию, заявив, что она нанесла урон неумышленно.
Правовое регулирование парсинга данных в Интернете в России
На основании ст. № 5 Закона «Об информации, информационных технологиях и защите информации»:
Информация является объектом отношений публичного, гражданского или иного правового характера. Ее может свободно использовать любое лицо или передавать другому, если ФЗ не ограничивает доступ к данным, или не содержится иных требований относительно порядка их предоставления и распространения.
С учетом категории доступа информацию делят на общедоступную и информацию с ограниченным доступом (посредством федеральных законов).
С учетом порядка предоставления или распространения информация бывает:
свободно распространяемой;
предоставляемой по соглашению участников соответствующих отношений;
подлежащей предоставлению или распространению на основании ФЗ;
ограниченной или запрещенной к распространению на территории РФ.
Российское законодательство вправе самостоятельно устанавливать категории информации с учетом ее наполнения или правообладателя. То есть, цены в магазинах — это общедоступная информация, поскольку нет закона, который ограничивает к ней доступ. Поэтому фотографировать и записывать стоимость товаров разрешено. В ст. 29 Конституции РФ сказано, что каждый гражданин имеет право на свободный поиск, получение, передачу, производство и распространение информации любым законным путем.
На основании действующего в РФ законодательства, позволено все, что не запрещает закон.

Источник: shutterstock.com
Парсинг данных с сайта — разрешенная процедура, если в ходе нее никак не нарушаются правовые аспекты. Остановимся на ограничениях.
Запрещено:
нарушать авторские и смежные права;
неправомерно применять доступ к компьютерным данным, охраняемым законом;
собирать информацию, относящуюся к коммерческой тайне;
заведомо недобросовестно пользоваться гражданскими правами (злоупотреблять ими);
использовать гражданские права для ограничения конкуренции.
Из перечисленных выше запретов вытекает, что компания вправе автоматически собирать данные (парсить сайты), размещенные в открытом доступе в интернете, если:
сведения находятся в открытом доступе и не защищены законом об авторском и смежном праве;
парсинг выполняется законным путем;
в результате сбора данных работа сайтов не нарушается;
в результате парсинга конкуренция не ограничивается.
Выполняя парсинг данных с сайтов, соблюдайте определенные правила:
извлекаемая информация не защищена авторскими правами;
процедура парсинга не тормозит работу сайта;
сбор данных не противоречит условиям использования ресурса;
парсер не извлекает личные (персональные) данные пользователя;
контент, подвергаемый парсингу, соответствует стандартам правомерной эксплуатации.
Наиболее тонким нюансом считается то, что сайты могут заявить о помехах, создаваемых парсингом, и убытках, вызванных процедурой. В оправдание приведите пример: поисковые механизмы Google и Yandex регулярно парсят (индексируют) ресурс и собирают все доступные данные.
Следовательно, вполне нормально, что подобный инструмент посещает сайт компании и собирает информацию о ценах, технически выполняя то же самое. Доказать влияние парсинга на скорость работы сайта очень сложно.
Как защитить свой сайт от парсинга данных
Каждый владелец интернет-магазина парсит данные, чтобы использовать их на другом сайте. Подобные интернет-площадки включают в себя многочисленные однотипные описания товаров, технические характеристики и прочий контент. Содержание интернет-магазина наполнено и унифицировано, и этим оно отличается от сайтов другого типа. Такой контент легко воспроизвести. Клиенту неважно, кто у кого позаимствовал текст — он запрашивает товар в поисковой системе и проходит на сайт по ссылке, предлагаемой или рекламой, или выдачей.
Можно крайне негативно относиться к использованию чужой информации. Но современный мир диктует свои правила, и интеллектуальная собственность воспринимается совершенно иначе. Кроме того, технические характеристики и описания продукта — это та информация, менять формулировку которой нет необходимости. Следовательно, у такого контента нет владельца. Однако копировать чужой магазин противозаконно, как и частично использовать текст, на который у вас есть права. Заметим, существует и другой термин — граббинг (от англ. grab, т.е. использовать, перехватывать) – сбор данных по определенным параметрам.

Источник: shutterstock.com
Парсинг (граббинг) данных с сайта создает проблемы разного характера: технического, коммерческого, психологического.
Суть технических проблем в том, что сканнеры и боты — пустой трафик, перегружающий сервер. Бывает, статистика говорит о значительном увеличении посещаемости и запредельной глубине просмотра, но радоваться, скорее всего, нечему. Это заслуга скрипта, его сканнеров и ботов. При наличии хостинга с ограничениями повышенную нагрузку стоит рассматривать и как проблему, и как знак начать расследование на предмет выяснения, кто вас сканирует.
Проблемы коммерческого характера также лежат на поверхности. Если конкурент начинает парсить данные из вашего интернет-магазина, формирует базу, а потом продает такую же продукцию по более низкой цене, вы теряете клиентов.
Ну и, конечно, психологические проблемы. Когда мы понимаем, что информацию крадут, то испытываем разочарование и обиду.
Давайте оценивать ситуацию объективно. Еще не придумали стопроцентно эффективного метода борьбы с парсингом и граббингом, а потому создавать типовой интернет-магазин со стандартным наполнением всегда потенциально опасно. Если же ваша торговая площадка популярна, то паразитный трафик должен стать толчком к развитию бизнеса в том направлении, которое легче защищать.
Помните о важности человеческого фактора, который позволяет формировать интеллектуальный продукт. Украсть его можно, но с доказательством авторства проблем нет. Потенциальные воры далеко не всегда хотят идти на риски и напрямую нарушать законодательство.
Как побороть парсинг, если он мешает работать? Меры бывают техническими, юридическими, психологическими.
Технические меры
Участники специализированных форумов непрерывно обсуждают технические методы борьбы с парсингом данных. То, что варианты решения проблемы существуют, радует. Но есть и минус: в будущем эти методы могут больше навредить, нежели оказаться полезными.
Самый легкий и эффективный способ — определять IP-адрес, с которого вас парсят, и перекрывать доступ. Для этого необходима таблица логов, куда вносят данные пользователя и время посещения страницы.
Распознать парсера можно разными способами, и один из них — отслеживание периодичности запросов. Слишком частые обращения (отклонение от среднего показателя дельты у 80 % менее 10 секунд) говорят о том, что вас парсят. Другой вариант распознавания — проверять, какой контент скачивают. Если, например, картинки или стили CSS, скорее всего, вы имеете дело с парсером.

Определите, какой бот посещает сайт — полезный или нет. Это достаточно трудно, поскольку многие выглядят вполне нормальными поисковыми ботами или браузерами, маскируясь соответствующим образом. Определить можно лишь по комплексу признаков, а для этого требуется специфическое самописное программное обеспечение.
Если не учитывать различные факторы,существует риск заблокировать поискового или еще какого-нибудь безопасного бота — не все они корректно представляются по user-agent. Кроме того, вредные снижают частоту обращений, чтобы не выдавать себя.
Блокировать IP-адреса разумно лишь в самых очевидных ситуациях, поскольку IP может быть выделен динамически. Но добавление ограничений на частоту обращений и заданного количества вхождений будет полезной мерой. Напомним, что все это относится лишь к одному способу.
Есть еще один вариант — использование разных сервисов, защищающих от DDOS-атак. Такие программы определяют, насколько загружен ваш сайт. Если количество подключений за секунду очень большое, парсинг воспринимается как DDOS-атака. На мониторе появляется задержка вместе с предупреждающей надписью. Парсинговая программа создает нагрузку в несколько потоков без пауз между закачиванием страниц. Иногда это помогает, но лишь против простейших ботов.
Третий способ — использование JavaScript, чтобы выполнять парсинг данных сайта. JavaScript при этом бывает разным. Из-за скриптов деятельность парсера значительно усложняется, поскольку программы не интерпретируют данные. Минус подхода в том, что положительным ботам из-за него также сложнее работать. Если неаккуратно использовать скрипты, сайт может просесть в поисковой выдаче или вылететь из нее.
Еще один способ — использование капчи, которую, конечно, никто не любит.
Способ можно было бы считать эффективным, исключив два минуса:
увидев капчу, пользователь раздражается, не может игнорировать ее, а потому менее лояльно относится к вашему сайту;
существуют сервисы по распознаванию капчи, которые постоянно улучшаются.
Результаты использования находятся под большим вопросом, если учитывать факт, что посетитель потеряет некоторый интерес к вашему ресурсу.

Полезнее применять ReCAPTCHA, поскольку она старается определять, передвигается ли пользователь по сайту.
Чтобы применять более хитрые методы, прикладывайте максимум сил. Для начала определите, что по сайту путешествует парсер, затем вычислите, после чего либо не препятствовуйте его работе, либо перекройте доступ. Использование технических инструментов зачастую не дает никакого результата. Вы будто боритесь против невидимого врага. Стараться можно, но шансов навредить себе больше.
И, наконец, способ, который без негативных последствий и постоянных усилий помогает предотвратить парсинг данных с сайта. Если обеспечить стопроцентную защиту от ботов нельзя, усложните использование содержимого своего сайта. Самыми ценными могут быть, к примеру, фотографии товаров. Проставляйте на картинках водные знаки, которые сложно удалить. Автоматически устранить их трудно, а восстановить исходную картинку для размещения на своем сайте — задача, которую захочет решать далеко не каждый.
Организационные меры
Одна из первоочередных задач заключается в обеспечении быстрой индексации новых страниц сайта, пока их не спарсили. Введите в поисковике запрос «авторство в Google и Yandex» и пользуйтесь всеми способами оповещения поисковых ботов о новых страницах. Метод эффективен лишь при условии уникальности контента.
По результатам мониторинга интернета (ручным запросам в поисковых системах, проверке на плагиат) можно установить, что ваши материалы кто-то позаимствовал. Если увидели, что контент скопировали, попробуйте поговорить с владельцем другого сайта. Результат переговоров вас не устроит? Предъявите претензии в юридическом порядке.
Нужно иметь четкое представление о свойствах информации в интернете:
Данные в сети распространяются в кратчайшие сроки. Из-за этого бывает технически сложно доказать, что именно ваш сайт — первоисточник.
Подавляющее большинство материалов в интернете не являются авторскими. Это разные комбинации из них. Здесь закон об авторском праве окажется бесполезным.
Правовая сторона, касающаяся интернета, проработана некачественно, а потому дополнительные судебные тяжбы могут лишь усугубить, а не разрешить проблему, особенно, с выгодной вам стороны.
Поисковики, будучи гигантами IT-отрасли, используют массу юридических лазеек. Вполне возможно, их применят и те, кто парсит ваши данные с сайта.
Разрешено предъявлять претензии, связанные с незаконным использованием фото и прочего контента, авторство на который доказать без проблем. В первую очередь, пожаловаться можно поисковым системам. Как минимум, сайт снова станет первоисточником. На основании жалобы применяются соответствующие действия: так, Google может наказать за единственное фото.
Насколько серьезные меры против парсинга можно предпринять, зависит от конкретного частного случая. Например, можно начинать бороться с парсерами, когда очевидно, что они пытаются извлечь с сайта персональную информацию. Утечка таких сведений дискредитирует ваш web-ресурс. Аудитория меньше доверяет, что снижает и посещаемость, и прибыль. В ряде случае это может закончиться борьбой с представителями исполнительных органов власти.
Но часто судебные разбирательства, касающиеся утечки контента, не приносят ожидаемых результатов. Требуется и время, и внимание, а затраты в итоге могут не окупиться.
Психологические меры
Здесь все зависит от вашего настроя, и насколько целесообразным считаете тот или иной подход. Хотите действовать жестко — примените технические или юридические меры, чтобы показать: парсерам проще найти другой ресурс, чем бороться с вами.
Уверены, что с парсерами легче договориться? Предложите сотрудничество. Если контент на вашем сайте востребован, всегда найдутся те, кто захочет его позаимствовать. Программа сделает парсинг данных с сайта в Excel, XML или YML. YML-файл – это документ, обрабатывающий «Яндекс» для своего «Маркета».

Источник: shutterstock.com
Иными словами, если не можете побороть явление, организуйте его: предлагайте условия сотрудничества, партнерские программы, создайте интерфейс экспорта информации и зарабатывайте на этом. Те, кто еще вчера заказывал парсинг данных, превратятся в ваших клиентов. Это позволит работать на взаимовыгодных условиях. Эффективно лишь в определенном сегменте рынка и конкретных типах бизнеса. Но благодаря организованным программам вы повысите посещаемость или размер прибыли.
*Facebook – организация, деятельность которой признана экстремистской на территории Российской Федерации.














